딥러닝 모델의 파라미터수가 크게 증가함에 따라 학습에 필요한 메모리도 함께 늘어나고 있습니다. OpenAI의 GPT-2는 1.5B개의 파라미터들로 구성되며 Google의 mT5도 13B에 이르는 파라미터 수를 가지고 있습니다. 또한 OpenAI의 GPT-3의 파라미터 수는 175B에 달합니다. 이렇게 큰 모델들의 경우 소규모 데이터로 fine-tuning을 시도하는 경우라고 해도 대량의 GPU 메모리가 필요하기 때문에 쉽게 시도해 보기 힘든 것이 사실입니다.
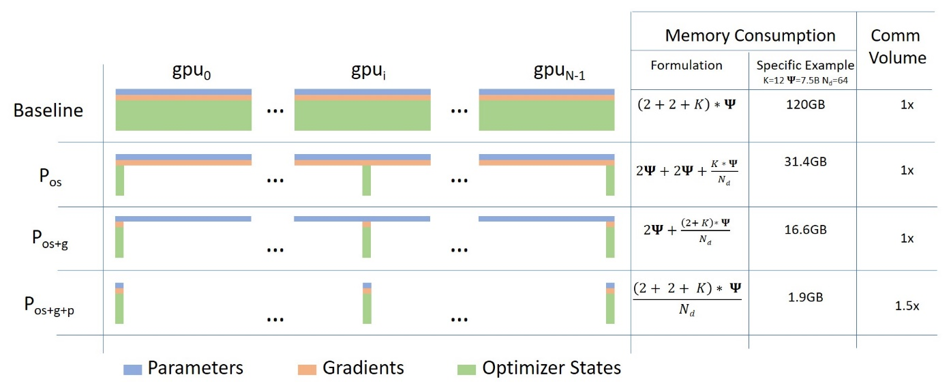
Microsoft에서 발표된 논문인 “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models”는 이러한 문제를 완화시키기 위한 기법들을 다루고 있으며 필요 최대 메모리 양을 크게 감소시킬 수 있다고 알려져 있습니다. 다음은 논문 링크입니다:
billions to trillions of parameters is challenging. Existing solutions such as
data and model parallelisms exhibit fundamental limitations to fit these models
into limited device memory, while obtaining computation, communicat…
Microsoft에서는 이 논문에서 구현된 다수의 기술들을 DeepSpeed라는 이름으로 공개하였습니다. DeepSpeed를 사용하면 기존 대비 메모리 요구량을 1/10으로 감소시킬 수 있어서 10배 큰 배치 크기, 혹은 10배 큰 모델을 사용할 수 있도록 해 준다고 합니다. Microsoft는 이 라이브러리를 사용해서 Turing-NLG라고 불리는 17B개 파라미터를 갖는 모델을 학습하였습니다. 한편, Facebook에서도 논문에서 구현된 기술을 FairScale이라는 이름으로 공개하였습니다. 다음은 DeepSpeed와 FairScale의 github 저장소 링크입니다:


또한, 자연어 프레임워크로 잘 알려져 있는 HuggingFace에서도 4.2.0버전에서 DeepSpeed와 FairScale을 구현하였고, 몇 가지 파라미터 설정만으로 쉽게 사용할 수 있도록 하였습니다. 예를 들어, 3B개의 파라미터를 갖는 mT5-3B 모델의 경우 RTX 3090 24G GPU 1개로는 배치 크기 1로도 메모리 에러가 나지만, DeepSpeed와 FairScale, FP16을 동시에 사용하면 배치 크기 20으로 학습이 가능하다고 합니다. 관련한 분석 내용들이 포함된 글을 공유합니다: