
[선행연구팀 김성현]
최신 언어 모델은 대규모의 코퍼스를 이용해 학습합니다. 특히, GPT-2, BART, T5 모델과 같이 디코더 신경망을활용한 모델의 경우, 다음 토큰을 반복적으로 샘플링하여 자연어를 생성해낼 수 있습니다. 여기서 샘플링의 방법에 따라 생성되는 자연어의 주제, 스타일, 정서 등과 같은 속성을 제어할 수 있습니다. 이번 포스팅에서는 자연어를 생성해낼 때 사용할 수 있는 효과적인 디코딩 샘플링 전략을 소개하고자 합니다. 잘 알려진 디코딩 전략은 greedy search와 beam search가 있습니다.
- Greedy search
Greedy search의 경우, 단순히 가장 높은 확률을 가진 단어를 다음 단어로 선택합니다.
수식으로 표현하자면, 𝑤𝑡=𝑎𝑟𝑔𝑚𝑎𝑥𝑤𝑃(𝑤|𝑤1:𝑡−1) 이며, t는 각각의 timestep을 의미합니다.
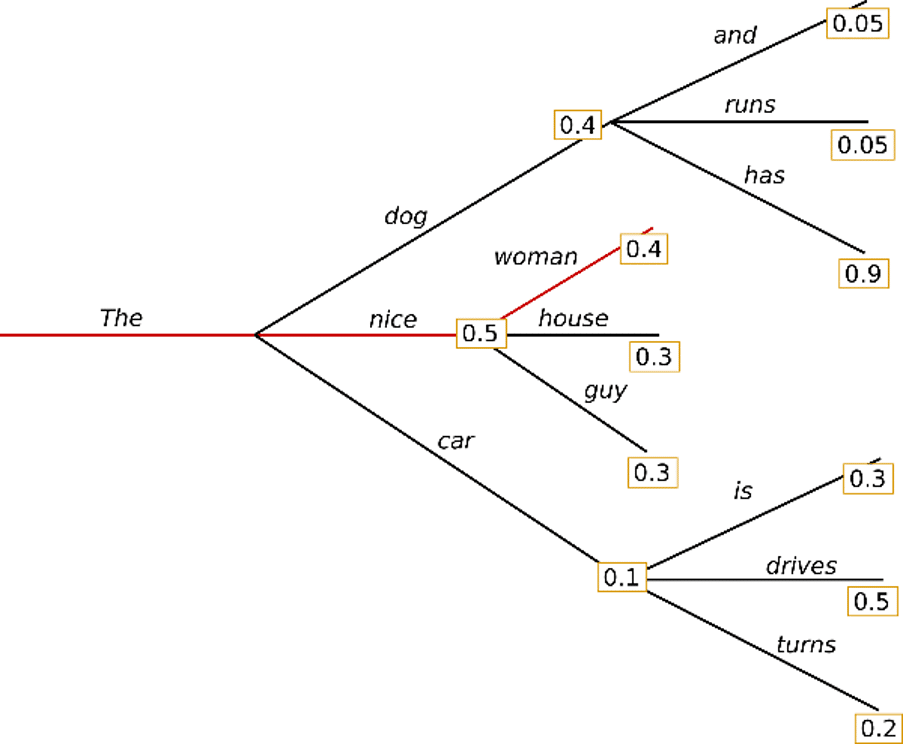
Greedy search 알고리즘은 단어 ‘The’ 에서 시작하여, 다음 단어로 가장 높은 확률의 단어인 “nice”를 선택할 수 있습니다. 최종적으로는 “The nice woman” 이라는 문장이 생성되며, 전체 확률은 0.5 * 0.4 = 0.2로 계산됩니다. 그러나 이 경우, 계속해서 특정 문구가 반복되어 생성될 것입니다.
- Beam search
Beam search는 트리 수준 당 특정한 숫자인 beam width만큼 확률을 탐색하고, 가장 높은 확률을 가지는 트리를 선택합니다.
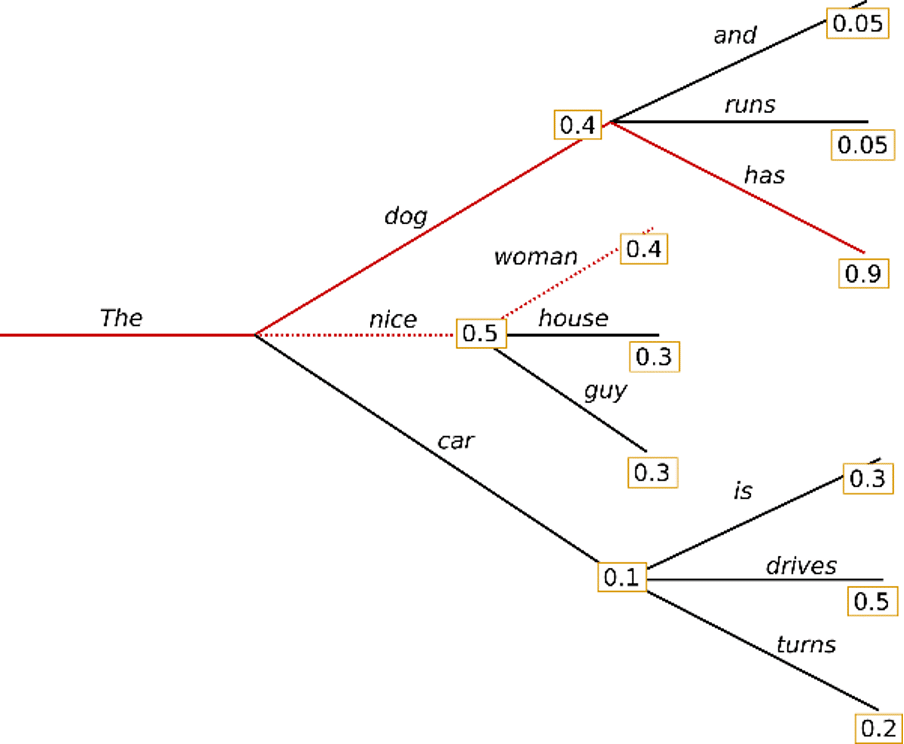
예를 들어, beam width를 ‘2’ 로 설정하였을 때의 예시입니다. 이 때, “The” 다음에 나올 수 있는 “dog”, “nice”, “car” 중에서, 나올 수 있는 가장 높은 확률을 가지는 2개의 가설인 “dog”와 “nice”를 함께 탐색하기 시작합니다.
결과적으로, greedy search로 선택되었던 “The nice woman” 의 확률인 0.2보다, “The dog has” 의 확률이 0.36으로 더 높은 것을 발견할 수 있었습니다. 이러한 Beam search의 경우, 다음의 특징을 가질 수 있습니다.
- 기계 번역이나 문장 요약 등, 원하는 문장 생성 길이가 예측 가능한 task에서는 잘 동작할 수 있습니다. 하지만 대화나 이야기 생성처럼, 출력길이가 크게 달라질 수 있는 개방형 생성에서는 원할하게 동작하지 않습니다. (Murray et al. (2018), Yang et al. (2018))
- Beam search는 반복 생성 문제에 취약합니다.
또한, Ari Holtzman et al. (2019) 논문에 따르면, 인간이 선택한 언어는 더 높은 분산을 가지게 된다고 합니다.
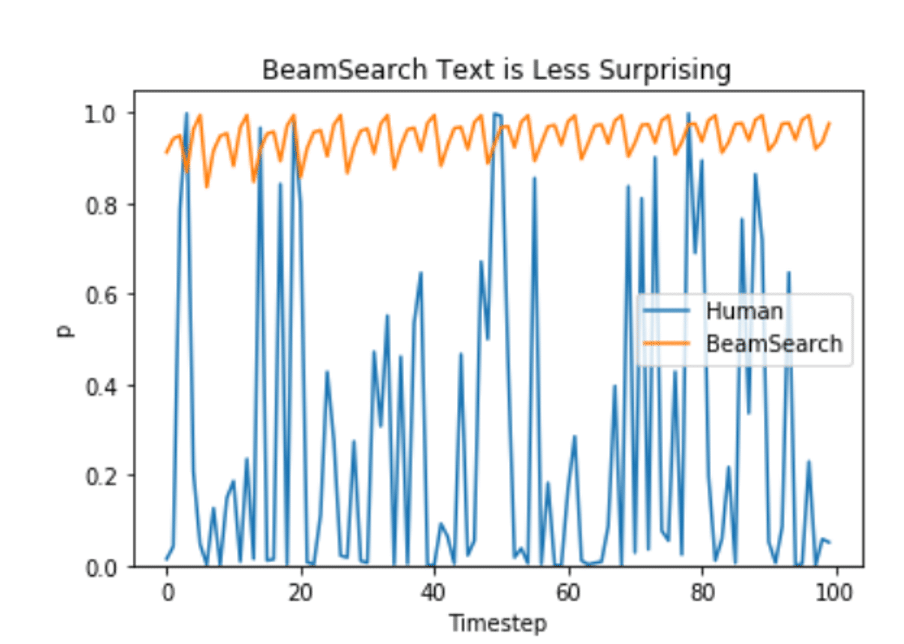
그럼 더 나은 생성 전략은 어떤 것이 있을까요?
아래 실습 코드를 통해 KoGPT-2 기반의 자연어 생성 전략을 살펴보겠습니다.
https://colab.research.google.com/drive/1yUGVmQ0nj8Hd3h0YV6PemQx0FtzpefGB?usp=sharing
references
https://lilianweng.github.io/lil-log/2021/01/02/controllable-neural-text-generation.html
https://huggingface.co/blog/how-to-generate






