
[서비스개발팀 전동준]
Unity에서 공개한 ML-Agents는 게임 환경의 가상 캐릭터를 만드는 오픈소스 툴 입니다. 게임 환경을 만들고 환경에서 작동할 수 있는 NPC 캐릭터(Agents)를 강화 학습등의 알고리즘을 통해 학습 할 수 있습니다. 2017년에 처음 공개되었고 1년 전에 v1.0이, 지난달에 다중 에이전트의 훈련을 지원할 수 있는 기능등이 포함된 v2.0이 공개되었습니다.
오픈소스로 공개된 툴킷에는 에이전트가 물체를 옮긴다거나, 특정 목표를 향해 이동하도록 만들어진 예제 학습 환경 18개가 구성되어 있어 사용할 수 있었고, 새로운 환경을 만들 수 있는 가이드도 제공하고 있습니다.

ML-Angets는 기본적으로 pytorch(https://pytorch.org) 기반의 모델을 만들어 onnx(https://onnx.ai)를 이용하여 컨버팅된 모델을 유니티에서 사용할 수 있었습니다. AI 연구자들에게 익숙한 Colab 환경에서의 예제들도 지원하고, OpenAI의 gym환경과도 호환될 수 있게 되어 있습니다. 학습 알고리즘에 대해서 큰 지식이 없더라도 구현된 최신 알고리즘들을 사용할 수 있게 되어있고, 가이드 문서도 잘 되어있습니다.
아래에서는 v2.0에서 새롭게 추가된 협동 행동 훈련 예제를 테스트 해보았습니다. ML-Agents의 예제중에 하나인 Dungeon Escape 환경인데, 3명의 에이전트와 1마리의 드래곤이 있는 환경에서 에이전트들이 드래곤이 도망가기 전에 죽여서 열쇠를 얻고, 던전을 탈출해야 하는 환경입니다. 기본적으로는 3명의 에이전트가 그룹으로 묶여서 던전을 탈출하면 보상을 받을 수 있습니다.

이 환경에서 처음에는 에이전트들이 헤매는 모습을 보이다가 학습을 진행하면 빠르게 던전을 탈출하는 모습을 볼 수 있습니다. 다음 영상은 2백만 step정도 학습한 결과인데요. 드래곤을 빨리 처치하고 던전을 빠져나가는 모습을 볼 수 있었습니다.
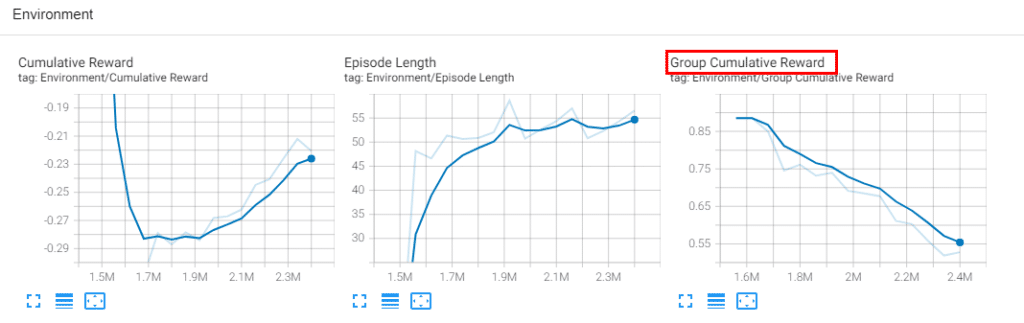
이 에이전트들에게 새로운 환경을 주고 테스트 해보고 싶어서, 드래곤을 죽이면 그 에이전트에게 페널티(-1점의 보상)를 주는 환경을 세팅해서 학습을 추가로 진행시켜 보았습니다. pretrained 모델을 다시 학습시킬 수 있게도 잘 되어있어서 앞에서 학습시킨 모델에 새로운 페널티를 주는 환경만 추가해서 2백만 step정도 다시 학습시켰더니 드래곤을 적극적(?)으로 피하는 모습을 볼 수 있었습니다.
사실 기대한 모습은 드래곤을 죽이면 개인에게는 페널티지만, 그룹 전체에게는 보상이 주어지는 환경에서 다른 두 명의 에이전트가 한 명의 에이전트를 떠민다는 행동을 하지 않을까를 기대했었는데 그런 행동이 보여지지는 않았고, 드래곤을 처치하면 페널티가 주어지기 때문에 드래곤을 처치하지 못하고 던전을 빠져나가지 못해서 그룹 전체 보상만 떨어지는 쪽으로 학습되는 것을 볼 수 있었습니다. tensorboard를 이용하여 학습 과정도 볼 수 있도록 연동되어 있습니다.
유니티 사용법과 학습 알고리즘에 대한 간단한 지식만 가지고 있다면 ML-Agents를 이용하여 재미있는 환경과 게임 캐릭터들을 만들어 볼 수 있을 것 같습니다.
github: https://github.com/Unity-Technologies/ml-agents







