

(https://www.forbes.com/sites/nishatalagala/2021/03/15/artificial-intelligence-in-2021-five-trends-you-may-or-may-not-expect/?sh=15e425135677)
[서비스개발팀 임창대]
DevOps가 나타나기 전까지는 On-premise 서버라고 해서 회사들이 각자 서버를 가지고 있고 서버 관리자, 개발자, QA가 따로 있었습니다. 이런 상황에서 서비스에 접속이 안되면 실제 물리서버를 사서 Rack을 만들고 서버를 꽂아서 설치하는 과정들을 수행했습니다. 이런 상황에서 개발을 해왔기 때문에 DevOps라는 개념이 없었고 필요를 느끼지 못했습니다. 하지만 현재는 데이터센터가 생기면서 코드 몇 줄 이면 서버가 만들어지고 코드 몇 줄 이면 원하는 스펙으로 서비스를 손쉽고 빠르게 만들 수 있습니다.
Devops 환경에서 개발자는 배포 및 유지보수 업무까지 수행 가능하게 되고 이는 기존의 Rack을 들여온다거나 서버 매니징을 하는 역할이 개발자에게 왔다는 뜻 입니다. 하지만 서비스를 구축하고 비즈니스 프로세스에 사용하기 시작하면 새로운 장애물이 나타나기 마련입니다. 이 때 개발자는 Devops 도입을 통해 IT 부서에 일일이 자원 요청을 하지 않을 수 있습니다. 필요한 자원을 스스로 배포하고, 필요할 때 확장할 수 있고 모델을 관리할 때 꼭 해야 하는 트래킹, 버전 관리, 데이터 처리 등도 스스로 할 수 있습니다.
이러한 Devops 환경에서의 소프트웨어 개발 과정(코드 작성 -> 테스트 -> 패키징 -> 배포)은 ML 서비스 개발 과정(데이터 수집/전처리 -> 모델 학습 -> 테스트 -> 배포)의 사이클과 시스템을 안정적으로 빌드하고 운영할 수 있도록 한다는 점에서 유사한 형태를 지니고 있습니다.
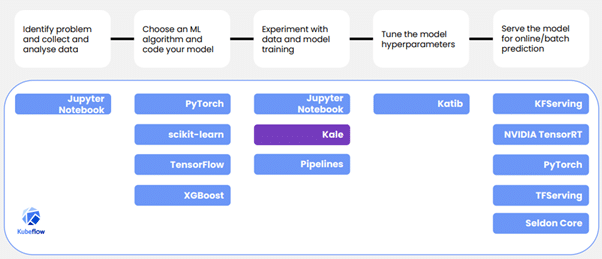
기존 Devops 환경의 개발과 달리 ML 은 데이터 관리와 지속적인 학습 과정이 필수적이라는 점에서 다음과 같은 점이 다릅니다.
- 팀 기술: ML 프로젝트에서 팀은 일반적으로 탐색적 데이터 분석, 모델 개발, 실험에 중점을 두는 데이터 과학자 또는 ML 연구원을 포함합니다. 이러한 구성원 중에는 프로덕션 수준의 서비스를 빌드 가능한 소프트웨어 엔지니어가 없을 수도 있습니다.
- 개발: ML은 기본적으로 실험적입니다. 특성, 알고리즘, 모델링 기법, 매개변수 구성을 다양하게 시도하여 문제에 가장 적합한 것을 최대한 빨리 찾아야 합니다. 도전과제는 효과가 있었던 것과 그렇지 않은 것을 추적하고, 코드 재사용성을 극대화하면서 재현성을 유지합니다.
- 테스트: ML 시스템 테스트는 다른 소프트웨어 시스템 테스트보다 더 복잡합니다. 일반적인 단위 및 통합 테스트 외에도 데이터 검증, 학습된 모델 품질 평가, 모델 검증이 필요합니다.
- 배포: ML 시스템에서 배포는 오프라인으로 학습된 ML 모델을 예측 서비스로 배포하는 것만큼 간단하지 않습니다. ML 시스템을 사용하면 모델을 자동으로 재학습시키고 배포하기 위해 다단계 파이프라인을 배포해야 할 수 있습니다. 복잡성을 추가하는 이 파이프라인을 사용하면 데이터 과학자가 배포하기 전 새 모델을 학습시키고 검증하기 위해 수동으로 수행되어야 하는 단계를 자동화해야 합니다.
- 프로덕션: ML 모델은 최적화되지 않은 코딩뿐만 아니라 지속적으로 진화하는 데이터 프로필로 인해 성능이 저하될 수 있습니다. 즉, 모델은 기존 소프트웨어 시스템보다 다양한 방식으로 손상될 수 있기 때문에 이러한 저하를 고려해야 합니다. 따라서 데이터의 요약 통계를 추적하고 모델의 온라인 성능을 모니터링하여 값이 기대치를 벗어나면 알림을 전송하거나 롤백해야 합니다.
MLOps는 ML 시스템 개발(Dev)과 ML 시스템 운영(Ops)을 통합하는 것을 목표로 하는 ML 엔지니어링 문화 및 방식입니다. MLOps를 통해 시스템 통합, 테스트, 출시, 배포, 인프라 관리를 비롯하여 ML 시스템 구성의 모든 단계에서 자동화 및 모니터링 환경을 구축하여 효율적인 개발 문화를 정착시켜보는 것도 좋을 것 같습니다.
MLOps: 머신러닝의 지속적 배포 및 자동화 파이프라인: https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning?hl=ko






