
[서비스개발팀 이경환]
우리는 보통 모델을 학습하는 과정에서 라벨이 없는 데이터 뭉치를 마주하게 되고, Data Annotation 문제에 종종 부딪히고는 합니다. 라벨이 없는 모든 데이터를 일일이 라벨링 하기에는 시간과 비용이 너무 많이 들기 때문입니다. 그러하기에, 무작위로 데이터를 선택하여 Annotation을 진행하는 경우가 많습니다. 무작위로 데이터를 선택하여 라벨링하는 경우, 모델의 성능 향상에 도움이 될 만한, 네트워크가 답을 예측하기 어려워하는 데이터의 비중은 낮을 확률이 높습니다. 이미 네트워크가 답을 예측하기 쉬워하는 데이터 위주의 학습이 이뤄진다면, 실제 네트워크가 예측하기 어려운 데이터가 나올 경우, 답은 맞추기 힘들 겁니다.
Active Learning은 모델이 어려워하는 데이터를 판별하여, 유저가 데이터 학습을 효율적으로 진행하도록 도와주는 기술입니다. 어떠한 방식으로 모델이 어려워하는 데이터를 판별하는 지가 Active Learning의 핵심입니다. 20여년 이상 발전한 기술인만큼 다양한 판별방법이 존재합니다. Uncertainty-Based Approach, Diversity-Based Approach, 그리고 Expected Model Change가 그 예입니다. 하지만 위 세 접근법은 범용적으로 쓰이기 힘들거나, 계산량이 많아 딥러닝 네트워크에 적용하기 힘들다는 이유 등 한계점을 갖고 있습니다.
Learning Loss for Active Learning (CVPR 19)은 범용적으로 쓰이면서, 딥러닝 네트워크에 적용시키기에 용이한 Loss prediction Module을 제안합니다.

메인 모델(타켓 모듈이라고도 불림, ex. 이미지 분류 모델) 옆에 또 하나의 네트워크인 Loss prediction module을 두어, Loss를 예측하는 방식을 선택하였습니다. Input data의 loss를 추정하여, 네트워크가 어려워하는 데이터를 판별해 학습시키는 방법입니다.
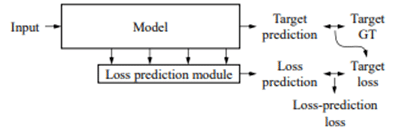
Loss function으로는 Margin Ranking Loss가 쓰였습니다. 상대적으로 많이 쓰이는 MSE(Mean squared loss) 방법을 사용하지 않은 이유에 대해 의문을 가질 수도 있지만, MSE를 활용할 경우, Target loss의 스케일이 계속 바뀌는 한계점이 있습니다. 따라서 Target loss의 스케일 변화에 영향을 받지 않는 Margin Ranking Loss를 활용하였습니다.

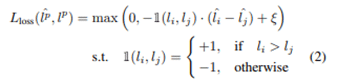
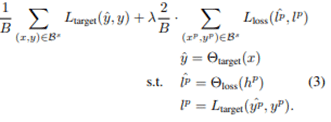
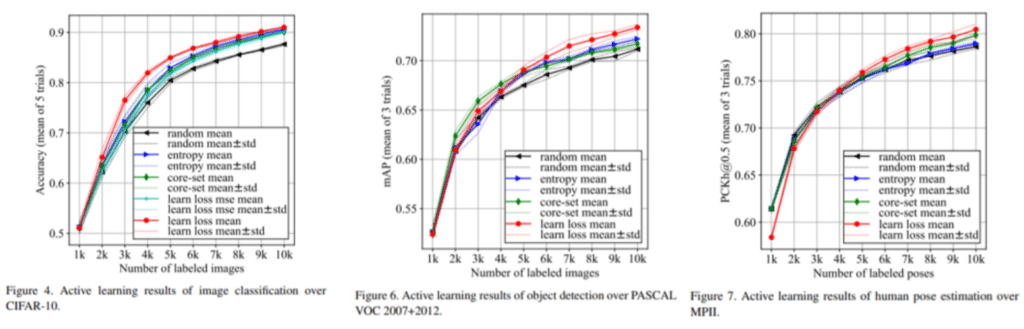
해당 논문에서는 Image Classification, Object Detection, 그리고 Pose Estimation 등 세 가지 Task에 대한 실험을 진행하였고, 다른 Active Learning 방법에 비해 상대적으로 좋은 결과가 나온 사실을 공유하고 있습니다. 각각 CIFAR 10 dataset / PASCAL VOC 2007 + 2012 dataset / MPI dataset 을 사용하였고, Random Sampling 방법, Entropy-based Sampling, Core-set Sampling 방법과 비교하여 성능의 우수성을 증명하였습니다. 세 과제에서 모두 기존의 방법론을 뛰어넘는 퍼포먼스를 선보였습니다.
AI 기술이 점점 더 발전하면서, 많은 양의 데이터를 라벨링해야 하는 경우가 빈번해지고 있습니다. Learning Loss for Active Learning에서 제시하는 Loss prediction module 솔루션을 활용해보는 것을 제시하며 글을 마치겠습니다.
Reference – 논문 : https://arxiv.org/abs/1905.03677
Reference – https://kmhana.tistory.com/10






