[선행연구팀 유희조]
TTS(text-to-speech)는 임의의 텍스트를 넣었을 때 해당 텍스트를 특정한 목소리의 음성으로 변환하여 산출하는 기술입니다. Google이 Tacotron 시리즈를 발표한 이후 HMM(hidden Markov model) 기반에서 딥러닝 기반으로 빠르게 전환되었으며 현재 상용 서비스되는 모델들 또한 딥러닝 기반으로 동작하는 경우가 많습니다. 상용화가 될 만큼 개선도 많이 이루어지고 있으며 관련 연구 또한 ‘단순 구현’에서 벗어나 점차 ‘새로운 기능’ 과 ‘최적화’ 를 고려하는 방향으로 진행되고 있습니다.
최근 네오사피엔스에서 이름 그대로 노래를 부르는 새로운 TTS 모델인 MLP Singer를 공개했습니다. 기존의 Non autoregressive Singing TTS로 공개된 Microsoft의 HiFiSinger가 Transformer에 duration predictor를 사용한 데 반해, duration predictor를 배제하고 Transformer 대신 MLP mixer를 사용함으로써 경량화 면에서 크게 향상된 모델입니다.
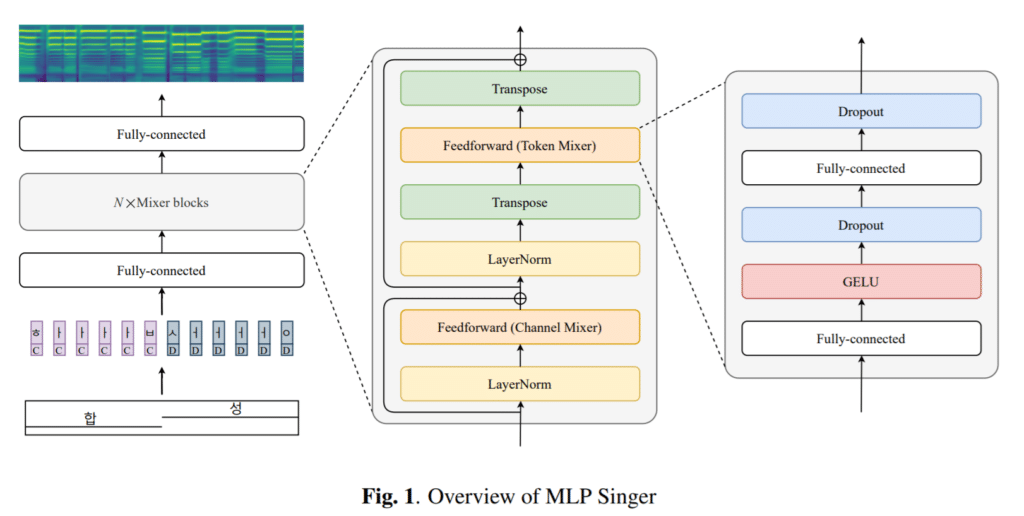
물론 최근 상용화되는 TTS의 MOS가 4점대를 넘어가며 거의 사람과 구분되지 않는 음성을 만들어내는데 반해서, 발표된 모델의 TTS는 아직 3점대 초반으로 개선의 여지가 많은 것으로 보입니다. 하지만 기존 TTS들이 그랬던 것 처럼 데이터의 축적과 모델의 정교화로 빠르게 발전할 것으로 기대됩니다.
카이스트 측에서 작년에 발표한 한/영 노래 데이터셋 또한 5월에 공개되어 해당 데이터로 학습된 데모를 공개되어 있으니 들어보셔도 좋을 것 같습니다. 좀 더 자세한 사항은 논문에서 공개된 데모 사이트인 밑의 링크를 참조하세요.
Demo link: https://mlpsinger.github.io/
Github link: https://github.com/neosapience/mlp-singer
Reference
Tae, J., Kim, H., & Lee, Y. (2021). MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis. arXiv preprint arXiv:2106.07886.
Choi, S., Kim, W., Park, S., Yong, S., & Nam, J. (2020, October). Children’s Song Dataset for Singing Voice Research. In The 21th International Society for Music Information Retrieval Conference (ISMIR). International Society for Music Information Retrieval.
Chen, J., Tan, X., Luan, J., Qin, T., & Liu, T. Y. (2020). Hifisinger: Towards high-fidelity neural singing voice synthesis. arXiv preprint arXiv:2009.01776.






