
[선행연구팀 송지현]
Open Domain chatbot에 관심을 갖고 Blender 1.0과 Meena에 관한 논문을 접한지 벌써 2년이 넘었습니다. 그 당시엔 그들이 향후 극복하겠다고 주장한 일관성 있게 롱 턴의 대화를 하고, 지식에 관한 정확한 응답을 하도록 만든다던 계획이 과연 몇 년안에 해결될 수 있을까 하는 의문이 있었습니다. 그 이유는 그동안 나온 Open domain chatbot들이 가진 한계는 저장한 데이터 기반의 검색을 하고, 대화가 길어지면 딴소리를 하며 없는 정보에 대해 물으면 애매한 답변을 하는 등의 인간의 대화와는 매우 거리가 멀게 느껴졌기 때문입니다.
그러나 이번 facebook AI에서 발표한 blender 2.0은 이전에 제시한 Open domain chatbot의 한계를 극복하였고, GPT-3 보다 뛰어나다는 평가를 받고 있습니다.
이번 글에서는 기존 모델에 대해 특징과 blender 2.0의 특징 정리와 관련 논문에 관한 리뷰를 함께 공유하려고 합니다.
과거 출시됐던 Google Meena & Facebook Blender 1.0의 특징


최근 출시된 Facebook Blender 2.0의 특징

위에 봇들의 특징을 비교해 보면 기존 봇과 최근 출시된 blender 2.0과의 차이는 멀티 턴에 대한 대화가 가능하며, 장기간 페르소나의 유지가 되고 인터넷 서치를 통해 실시간 정보가 업데이트 될수 있다는것입니다.
위 blender 2.0의 특징(왼쪽 이미지)을 보면 대용량 데이터를 학습시킨 GPT-3 는 과거 정보를 답변으로 제공하고 되묻는 반면 blender2.0은 최신 정보를 답해줍니다. 그리고 이전에 출시된 blender 1.0 은 질문에 대해 답변을 모르면 애매하게 되묻는 반면, blender2.0은 서치해 새로운 정보를 대화에 반영하여 자연스러운 답변을 합니다. Bot의 실시간 서치하는 기능이 대화하는 상대방에게는 정보습득 뿐만 아니라 자연스러운 대화를 이어가는데 도움이 많이 되는 듯 보입니다.
Facebook AI에서는 이 한계를 극복하기 위해 어떠한 노력을 했을까요? 아래에 최근 출시된 논문 중에 하나를 리뷰해 보았습니다.
Facebok AI Blender 관련 논문 리뷰 : Beyond Goldfish Memory: Long-Term Open-Domain Conversation
기존 오픈 도메인 챗봇의 장기기억에 한계점을 극복하기 위해 이전 대화를 요약하고, 회상할 수 있는 기능을 넣고 정보를 검색하고 업데이트 하는 방식이 기존 모델들과 비교해 더 좋은 성능을 냈다고 얘기하고 있습니다.
- Multi-Session Chat : MSC
본 논문을 보면 장기 메모리를 해결하기 위해 많은 정성을 들여 데이터 셋을 구축하였고, 이 데이터를 fine tuning 하는데 사용했습니다.- Session 1에서는 기존 PERSONACHAT인 짧은 대화 내용을 바탕으로 처음 만난 두 사람의 간략한 정보만 서로 나누는 대화 태스크로 진행이 됩니다.
- Session 2~4까지는 정해진 시간의 term(1~7시간 단위 또는1~7일 단위)을 두고, 기존 persona를 유지하고 이전에 했던 대화를 반영한 대화를 나누게 합니다. 마치 이전에 대화하다가 시간이 흘러 다시 대화를 나누는 두 사람처럼 주제가 확대될 때도 이전에 나눈 대화와 일관성이 있게 대화를 진행하게 합니다.
- Conversation summaries (확장된 persona) 워커간에 이전 대화를 볼 수도 있고, 이전 히스토리의 파악이 가능한 환경을 주더라도 사람은 제한된 시간내에 그 정보를 읽고 활용하기는 한계가 있기 마련입니다. 따라서 각 session에서 중요 포인트를 기록하고 요약하여 대화의 참고 자료로 활용하게 합니다.
- Dataset statics를 보면 이전에 구축한 짧은 2.6 ~ 14.77의 짧은 턴에 비해 MSC는 53 ~ 66턴 등의 긴 발화수를 가집니다.
- Modeling Multi-Session Chat
- Transformer Encoder-Decoders
기존 blender1.0에서 구축한 BST 2.7B를 pretrained Model으로 사용하고, 위에 MSC를 사용하여 fine-tune을 진행합니다. - Retrieval-Augmentation
검색 시스템은 디코더에 의해 제공되는 최종 인코딩에 포함될 컨텍스트의 일부를 찾아 선택하는데 사용됩니다. - Summarization Memory-Augmentation
이는 두 개의 메인 컴포넌트로 구성이 됩니다.
1. encoder-decoder 요약기 : 이는 마지막 대화에 포함된 새로운 정보가 있으면 장기기억 장치에 추가하는 기능을 합니다.
2. memory-augmented 생성기 : 대화 컨텍스트와 장기 메모리에 접근하여 다음 답변을 생성하는데 사용됩니다.
- Transformer Encoder-Decoders
- Experiments
- Using session dialogue context
- Using summary dialogue context
- Comparing performance on session openings
- Comparing different context lengths
- Summary context performance
- Varying the number of training sessions
- Predicted summary models
- Retrieval-augmentation model
- Summary Memory model variants
- Human Evaluation
5번째 session까지 대화를 나누고 이전에 대화를 나눈 4개의 session에 대해서는 요약을 제공합니다.
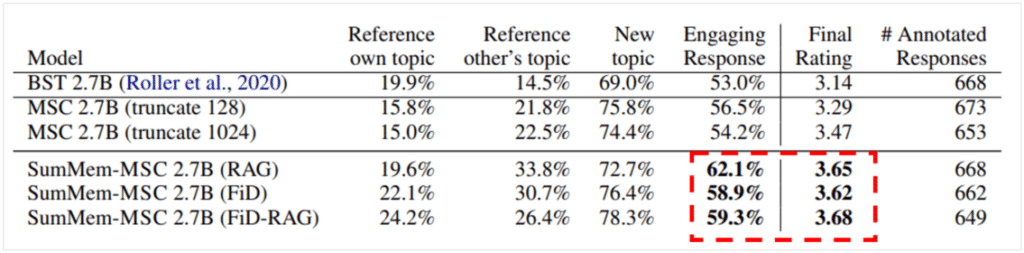
- Conclusion
본 연구에서는 이전 모델들이 가진 장기기억에 대한 한계를 다양한 아키텍처의 조사와 새로운 크라우드 소스 작업인 Multi-Session Chat을 통해 데이터를 수집하여 극복하였습니다.
자동 메트릭과 휴먼 평가 모두에서 뛰어난 결과를 얻었으며 향후 작업에서는 긴 컨텍스트와 대화 설정을 위한 아키텍처의 추가를 위해 연구하겠습니다.
Blender 2.0은 사람과 비슷한 개인화 정보를 갖고, 기억을 가지고 있으면서 학습에 의한 지식이 아닌 실시간 검색을 통해 정보를 제공하는 기능을 추가했습니다. 이는 Large모델을 학습해야 하는 수고를 덜어주는 혁신을 이루어 냈습니다.
다음엔 또 어떤 chatbot이 우리를 놀라게 해줄까요. 구글이 Meena2.0을? 아니면 Facebook 연구팀이 다음 버젼인 blender 3.0을? 앞으로 또 어떤 성능 좋은 기술이 나올지 두근두근 기대해 봅니다.
참고자료
https://ai.facebook.com/blog/blender-bot-2-an-open-source-chatbot-that-builds-long-term-memory-and-searches-the-internet/
https://arxiv.org/abs/2107.07567






