
[융합연구팀 송지현]
Microsoft는 기존의 시각데이터(image and video)를 활용하여 새로운 시각데이터를 생성하고 조작할 수 있는 multimodal pretrained model인 NUWA를 발표했습니다.
아래 그림은 8개의 다운스트림에 대한 시각적 합성 기술을 연구한 결과입니다.
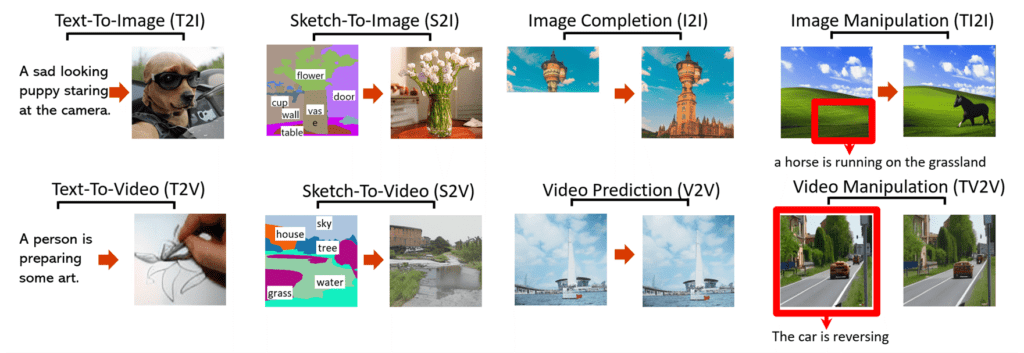
서로 다른 시나리오에 대해 text, image, video를 동시에 다루기 위해 3D transformer encoder-decoder framework를 설계 했습니다. 이 프레임워크는 video를 3D 데이터로 처리할 수 있을 뿐만 아니라 텍스트와 이미지에 1D와 2D인 데이터로 적응도 가능하게 처리할 수 있습니다. 계산 복잡성을 줄이기 위해 3D Nearby Attention(3DNA) 메커니즘도 제안했습니다.
NUWA는 텍스트-이미지 생성에 대한 최신 연구 결과와 비교하여, 텍스트 대 비디오 생성, 비디오 예측에서도 우수한 성능을 보여줬습니다.
또한, NUWA는 가이드 된 텍스트에 대해 이미지 조작 뿐만 아니라 비디오 조작에서도 놀라울 정도로 우수한 zero-shot 성능을 보여줬습니다.
Related works
• Visual Auto-Regressive Models : 본 연구에서는 비주얼 토큰화를 위해 NUWA에서 VQ-VAE 대신 VQ-GAN이 사용되는데, 이는 실험을 기반으로 더 나은 생성 품질로 이어지게 하는 것을 볼 수 있습니다.
• Visual Sparse Self-Attention : 본 연구에서는 시각적 생성에 대해 local-wise sparse attention가 axial-wise sparse attention 보다 우수하다는 것을 검증합니다.
Method
• 3D Data Representation : 모든 text, image, video 또는 그들의 sketch를 포함하기 위해 본 연구는 모든 것을 토큰으로 보고 통일된 3D 표기법을 정의합니다.(아래 그림 참고)
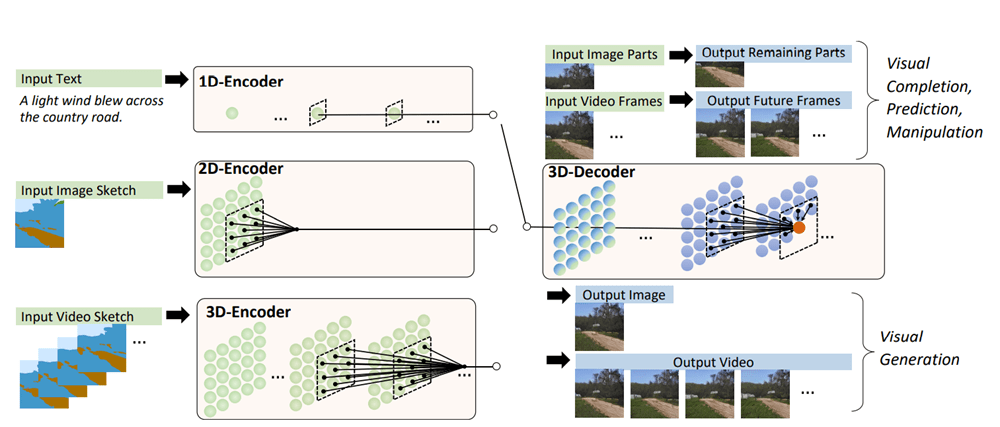
• 3D Nearby Self-Attention: 이전의 3D 데이터 표현을 기반으로 한 3D Self-attention(3DNA) 모듈, self-attention and cross-attention 지원합니다.
• 3D Encoder-Decoder: 3DNA를 기반으로 구축된 3D 인코딩-디코더를 도입합니다.
Qualitative comparison with state-of-the-art models for Text-to-Image (T2I) task on MSCOCO dataset
(아래 그림에서 빨간 박스: input에 대한 NUWA의 결과)

Quantitative comparison with state-of-the-art models for Text-to-Video (T2V) task on Kinetics dataset

NUWA는 다른 최신 모델들에 비해 성능이 뛰어나고, 시각적인 분야의 창조를 가능하게 하고 콘텐츠 제작자를 돕기 위한 AI 플랫폼 구축을 향한 본 연구의 첫 번째 단계입니다.
Microsoft가 연구한 NUWA를 필두로 text, image, video 등을 동시에 고려한 프레임워크의 개발과 공간 및 시각 축 모두의 인접 특성을 고려하는 nearby-sparse attention mechanism 그리고 위에서 보여주는 8가지 합성에 대한 포괄적인 실험을 통해 수 많은 발전과 기여점에 대해 찬사를 보냅니다.
참고 자료: https://github.com/microsoft/NUWA
https://arxiv.org/abs/2111.12417






