
[AI Lab 김무성]
스탠포드의 CS25 : Transformers United 강좌 동영상이 최근 공개 되었습니다. [1]
강좌[2] 자체는 작년 하반기입니다만, 그간 슬라이드만 공개하고 있었습니다. 그런데 이번에 동영상도 유튜브를 통해 공유했습니다. 슬라이드 자료도 참 좋지만 그래도 역시 직접 발표를 듣는 것만은 못하죠. 최근 딥러닝의 흐름과 해당 연구자들의 인사이트를 생생하게 들을 수 있어서 이번 포스팅 토픽으로 잡아보았습니다.
아마 이 글을 보시는 대부분의 분들이 구글의 트랜스포머[3] 모델에 대해 알고 계시리라 생각합니다. 하지만 아무래도 트랜스포머 모델의 주요 응용분야가 자연어처리 영역이었고, 트랜스포머 구조가 도입되면 모델이 커지는 경향이 있어서 ‘내 분야에는 안맞아’라고 하시는 분들도 있었을거에요. 하지만 요즘 트랜스포머가 사용되는 분야가 엄청나게 빠른 속도로 확장되고 있습니다. 그런 의미에서 단순 자연어처리를 넘어서서 어떤 분야에 어떤 식으로 도입되고 있는지를 알 수 있는 좋은 자료입니다.
어떤 연구자들은 트랜스포머 모델을 딥러닝계의 트랜지스터 발명처럼 생각하기도 합니다. 개인적으론 이보다 더 효율적인 구조의 모델이 나올 것 같습니다만, 그래도 당분간은(혹은 어쩌면 꽤 오랜 기간) 딥러닝 기반 AI 시스템의 주요 레고블록으로 트랜스포머를 사용하게 될 것 같습니다. 여러 이점이 있는데, 주로 연구보다는 산업적 응용의 이점이 큽니다. 상업성이 있는 데이터 기반 AI 시스템을 구축하는데는 생각보다 모델 이상의 많은 컴포넌트들이 필요한 것으로 밝혀지고 있습니다. 아래 보이는 그 유명한 그림처럼 말이죠[4]. ML Core 외에 필요한 다른 시스템들과 프로세스를 구축하느라 현장에서는 MLOps라는 이름으로 매우 고군분투하고 있습니다. 그런데 저 MLCore로 들어갈 모델이 단순해지면 정말 많은 이점이 있습니다.

트랜스포머 기반으로 구성하게 되면 그게 가능해지지 않을까라며 시도하는 많은 연구들이 나오고 있습니다. 이미지, 텍스트, 음성, 로봇 액션 등을 토크나이징 -> 토큰 시리즈 -> 포지션 임베딩 -> 토큰 예측 로스 등으로 일원화하는 것이죠. 부분적으로 성공도 했구요[5] (딥마인드의 어떤 연구자는 미리 ‘게임 오버’라며 선언하기도 했지만 이건 좀 더 지켜봐야겠죠).

트랜스포머 중심으로 AI 아키텍쳐를 구성하면 규모를 키우기에도 좋습니다. 물론 ‘점점 모델 크기만 크게하는 치킨 게임으로 가고 있다’라며 못마땅해하는 연구자들도 있지만, 당분간 이를 주도하는 빅테크 기업/연구소는 이를 계속 시도할만한 여러 이유가 있습니다. 이런 조직들은 비록 이렇게 규모가 커진 AI 시스템 자체는 상업성이 떨어지지만 클라우드를 비즈니스 주력으로 삼거거나 API 호출당 과금형태 해서 규모의 경제로 여러 사용자/기업들에게 판매하여 학습/추론 비용을 낮춘다던가 하는 식으로 꽤 극복해 낼 수 있습니다. 그리고 AI 산업 경쟁을 돈의 싸움으로 전환시켜 경쟁 그룹보다 앞서나갈 수 있고 미래 인프라를 차지하게 될 수도 있죠.
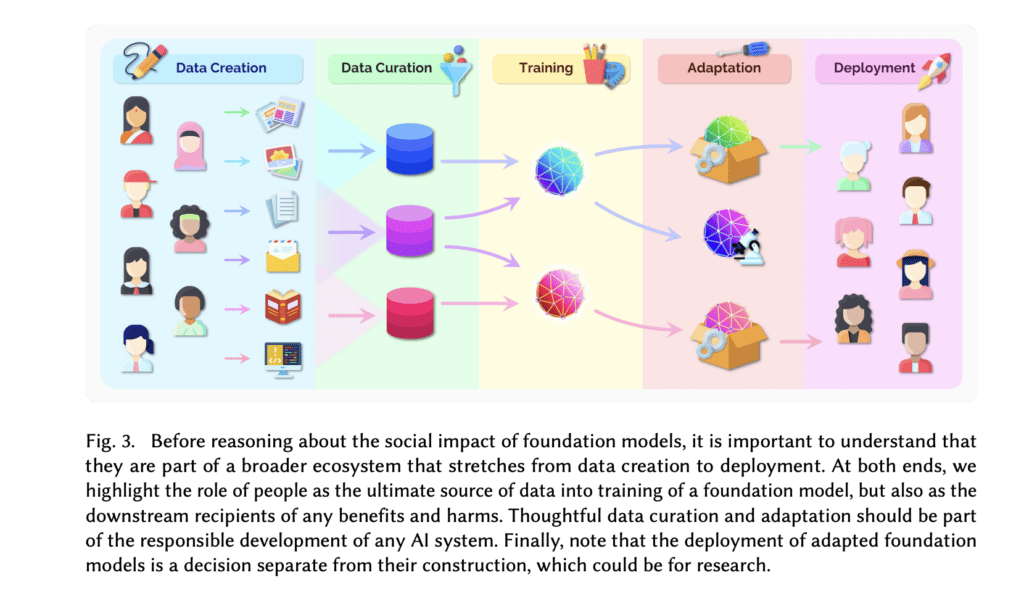
중소규모 기업/연구조직의 AI기획/MLOps/ML 응용 어플리케이션 개발자들도 트랜스포머 기반으로 확장되고 있는 현재의 흐름을 이해하는 것은 꽤 많은 이점이 있습니다. 물론 이른바 파운데이션 모델[6]이라 부르는 멀티모달-멀티태스크 모델들을 직접 학습/구성하는 것은 어렵습니다. 하지만 이런 거대규모 파운데이션 모델들이 가지는 ‘전이 학습’ 능력은 ‘few-shot learning(퓨샷 러닝)’이나 ‘Prompt learning(특히 in context learning 방식)’ 등으로 이전보다 더 적은 데이터로 더 쉬운 학습방식(혹은 비학습 방식)과 추론 방식을 활용할 수 있게 되고 있습니다. 산업응용의 측면에서는 아래 그림처럼 개발-개선 프로세스가 단순화될 수 있습니다. 거기에 더해 허깅페이스의 transformers [7] 라는 라이브러리 중심으로 좋은 도구 생태계가 마련되어 있고 점점 확장되고 있기에 어느정도 균질화된 AI 응용 어플리케이션 인력을 채용/교육할 수 있습니다. 심지어 GPU/TPU[8] 등의 딥러닝 전용 가속화 기기들이 on-demand로 클라우드에서 사용할 수 있고, JAX/Flax 등의 속도향상된 파이썬 라이브러리 기반 구현체들이 해당 라이브러리에 통합되고 있습니다. 이들을 활용하면 BERT나 GPT-2 등의 모델은 처음 등장했을 때와 비교해서 소/중형 모델이라고 할 수 있으니 적절하게 초대규모 모델과 미디엄 모델들을 활용하여 효율적인 시스템을 구성하기 쉬워지고 있습니다. 아마 현재 불붙고 있는 NPU 연구들이 어느 정도 성과를 보이게 될 근미래에는 트랜스포머 기반 파운데이션 모델을 API 호출이 아닌 방식으로 운영하는 것도 ROI가 나오는 상황이 되겠죠.
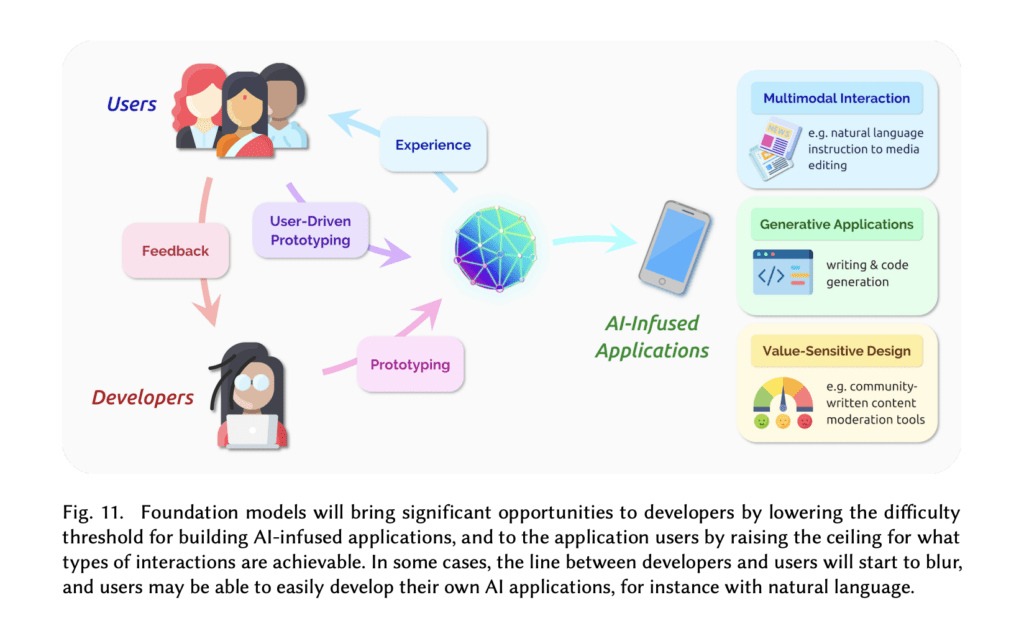

연구자로서도 트랜스포머 기반 연구들의 최신 흐름을 따라가는 것은 많은 이점이 있습니다. 여러 영역을 단일한 아키텍쳐로 넘나들 수 있으며, 거대화되고 있는 모델들에서 파생되는 여러 문제들을 미리 체험해보거나 대비할 수 있습니다. 퓨샷, 제로샷 현상들, 멀티모달 멀티토큰, 규모가 커지면서 출현하고 있는 여러 현상들. 물론 직접 이런 규모로 만들 수 없는 상황에 있는 연구자나 연구집단이 더 많겠지만 그래도 API 호출이나 파인튜닝, 또는 조금씩 공개되고 있는 오픈소스형 거대모델들을 통해 간접적으로 연구할 수 있고 대비할 수 있습니다. 또한 MLOps의 다른 영역들로 연결되는 지점으로 연구역량을 확장할 수 있습니다. 어떻게 규모가 커지는 모델을 서빙할지 – 모델/데이터 병렬화 라던가, Foundation Model에 자기만의 특화된 데이터를 어떻게 결합하고 상호운용할지에 대한 Data-Centric AI라던가 말이죠.
그리고 현재는 트랜스포머를 통해 진행되지만, 나중에 트랜스포머를 대체한 더 좋은 모델이 나오더라도 MLCore만 교체되지 나머지 부분들들은 아마도 여전히 핵심적인 형태로 남아서 – 10%의 영감으로 멀티모달-멀티태스크 Foundation Model을 엔진처럼 구성하고, 이 모델이 내뱉는 강력하지만 부정확한 결과물들을 보정하고 제어하고 해석하려고 애쓰는 90%의 노력의 형태로 – 계속 실무자/연구자들에게 도전과 보상을 부여할 것이라고 생각합니다.
——————
참고자료
[1] Stanford CS25: Transformers United (Autumn 2021) youtube – https://www.youtube.com/playlist?list=PLoROMvodv4rNiJRchCzutFw5ItR_Z27CM
[2] CS25: Transformers United Stanford – Fall 2021 – https://web.stanford.edu/class/cs25/
[3] Attention Is All You Need / Google / 2017 – https://arxiv.org/abs/1706.03762
[4] Hidden Technical Debt in Machine Learning Systems / Google / 2014 – https://research.google/pubs/pub43146/
[5] A Generalist Agent / DeepMind / 2022 – https://arxiv.org/abs/2205.06175
[6] On the Opportunities and Risks of Foundation Models – https://arxiv.org/abs/2108.07258
[7] hugging face’s transformers – https://huggingface.co/docs/transformers/index
[8] Cloud TPU – https://cloud.google.com/tpu






