
썸네일 출처: Dreambooth
[가상생명연구팀 심홍매]
올해 5월에 구글에서는 텍스트 입력을 기반으로 사실적인 이미지를 생성할 수 있는 텍스트-이미지 확산 모델(Diffusion Model)인 Imagen을 공개하였는데요, 몇개월이 지난 최근에는 사용자가 입력한 개체(subject)를 이해하고, 해당 개체 기반으로 다양한 형태의 이미지를 생성 할 수 있는 개인화가 가능한 텍스트-이미지 생성 모델 DreamBooth 를 공개하였습니다.
DALL-E2, Stable Diffusion, Imagen 및 Midjourney 등 텍스트-이미지 도구들도 주어진 텍스트에 따라 고품질의 다양한 이미지를 생성 할 수 있습니다. 하지만 이러한 최신 모델들은 reference 세트에서 사용자가 원하는 subject를 모방하고 다른 맥락에서 해당 subject의 새로운 표현을 합성하는 능력이 부족합니다.
예를 들어 아래 [그림 1] 시계 이미지(시계판 오른쪽에 노란색 숫자 3 크게 표기됨)의 경우 Imagen, Dall·E 2 등과 같은 모델은 시계 모양, 기능에 대한 설명을 텍스트로 추가함에도 불구하고 수십 번 반복 생성 한 후에도 여전히 기존의 시계 모양을 재 구성할 수는 없었습니다.

위의 문제를 개선하기 위하여 Google 연구원 Nataniel Ruiz 등은 Imagen 모델을 fine tuning하여 이미지에서 실제 객체를 사실적으로 복원하는 기능을 구현했습니다. 위 사진 중 맨 오른쪽에 새로운 모델 Dreambooth가 생성한 사진 내 시계에서 숫자 3의 위치를 더 잘 복원한 걸 볼 수 있습니다.
DreamBooth의 가장 큰 특징은 바로 개인화가 가능한 것인데요, 이러한 개인화를 표현하기 위해선 subject에 “고유 식별자”를 추가하는 방법을 이용하였습니다. 즉 원본 이미지 생성 모델에서는 [cat], [dog]등과 같은 개체의 유형(class)만 입력으로 받지만, Dreambooth는 개체를 표현할 수 있는 이미지 사진과 개체의 유형(class)을 입력 정보로 사용하여 fine tuning함으로써 앞의 개체를 “고유 식별자” [V] 로 인코딩한 텍스트-이미지 확산 모델을 얻습니다. 아래 그림을 예로 들면, 사용자가 3개의 강아지 사진과 그에 대응되는 클래스 이름 (예:”dog”)를 입력 정보로 사용하여 강아지 정보를 표현한 “고유 식별자”[V]와 해당 [v]정보를 인코딩한 fine tuning/개인화된 텍스트-이미지 확산 모델을 얻습니다. 추론 시 사진 내의 강아지 정보를 “a [V] dog”로 표현하고 추가로 생성하고자 하는 텍스트를 입력 정보로 사용함으로써 해당 개체가 포함된 원하는 이미지들을 생성 할 수 있게 됩니다.
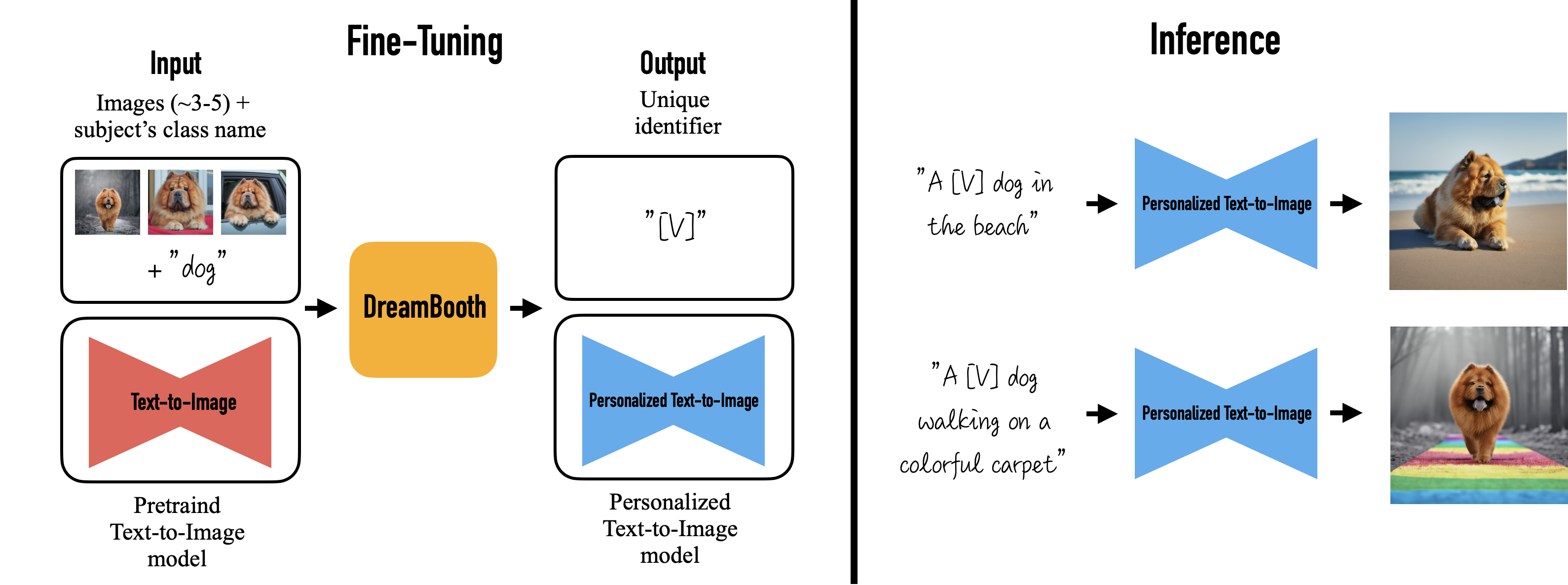
Dreambooth는 개인화가 가능한 텍스트-이미지 확산 모델로서 다양한 생성 능력을 갖고 있습니다.
아래 그림를 보면 사용자가 생성하고 싶은 강아지의 이미지 사진 4장 정도를 입력하고 , “in the acropolis”를 입력하면 사용자가 지정한 강아지가 acropolis에 있는 이미지가 생성 된 걸 볼 수 있습니다. 이외에도 “swimming”, “getting a haircut” 에 대해서도 모두 기존의 강아지 표현을 유지하면서 입력한 텍스트 표현에 대응되는 이미지가 자연스럽게 생성된 걸 볼 수 있습니다.

만약 당신이 반려동물을 기르고 있다면, Dreambooth의 “배경 전환 능력”을 이용하여 집을 떠나지 않고도 반려동물을 후지산이나, 베르사유 궁전 등으로 랜선 세계 여행을 보낼 수도 있습니다.

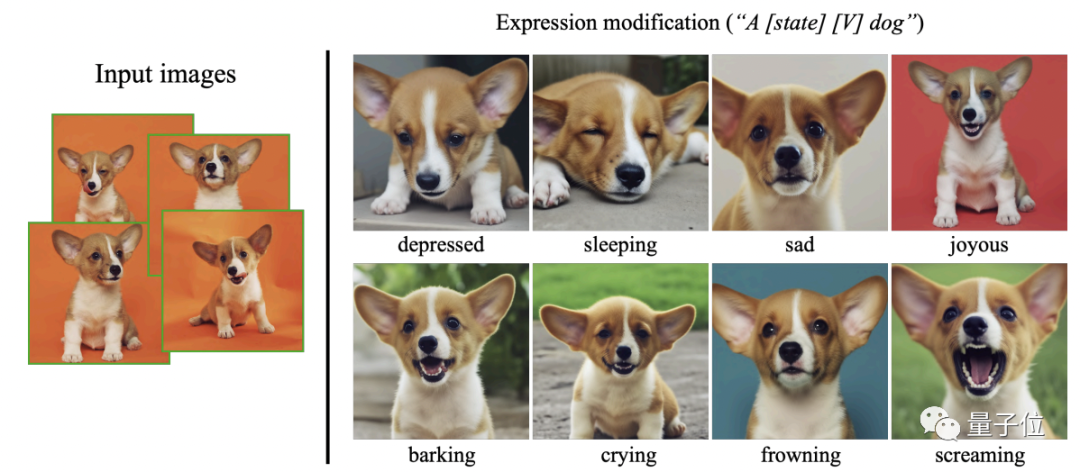
뿐만 아니라 반려동물의 움직임과 표정도 임의로 지정할 수 있어 말 한마디 만으로도 반려동물의 모든 가능한 상황들을 이미지로 생성 할 수 가 있습니다.
위의 “기본 생성” 외에도 DreamBooth는 “필터 추가”와 같이 사진을 다양한 스타일로 변경할 수도 있습니다. 예를 들어 아래와 같이 사실적인 강아지 사진에 대하여 “세계 명화 ” 스타일로도 변경을 하거나 “악세사리”를 추가하여 다양한 스타일로 코스프레이가 가능합니다.

동물뿐만 아니라 선글라스, 학교 가방, 꽃병과 같은 다른 물건에 대해서도 리얼한 이미지들도 생성할 수 있어 사용자들에게 창의성을 발휘하여 무궁무진한 새로운 작품을 생성 할 수 있도록 도움을 줄 수 있습니다.

Dreambooth는 한계점들도 존재하는데요, 아래 그림과 같이 “a [V] backpack in the ISS” 및 “a [V] backpack on the moon” 와 같은 프롬프트에 대해서는 이미지를 잘 생성하지 못하는데요, 논문에서는 가장 큰 원인은 , 모델에 프롬프트와 관련 된 학습 데이터가 적기 때문이라고 제의를 하고 있습니다. 또다른 이슈는 아래 그림 중 (b)와 같이 입력한 이미지의 개체와 프롬프트의 내용이 얽힘(entanglement) 현상이 발생함으로써 개체에 대한 모양 등이 변경되는 케이스도 있습니다. 이외에도 프롬프트가 업로드한 실제 이미지와 설정이 유사할 시에는 과적합 현상이 발생하는 경우도 있습니다.

대부분의 텍스트-이미지 생성 모델은 단일 텍스트 입력을 기반으로 이미지를 생성하지만, DreamBooth는 생성하고자 하는 개체가 캡쳐된 이미지 3~5개만 입력하면 개체의 특징을 유지하면서 다양한 관점에서 이미지를 재현할 수 있습니다. 물론 일부 악의적인 사용자들은 이렇게 생성 된 이미지를 사용하여 대중을 속일 수도 있습니다. 하지만 해당 문제는 기타 텍스트-이미지 생성 모델이나, 콘텐츠 생성 기술 관련 분야에서도 해결해야 할 공통적인 문제입니다. 향후 특히 개인화 생성 관련 연구 시에는 위의 이러한 문제점들을 인식하고 개선을 하기 위해서는 지속적으로 노력을 기울여야 할 것 같습니다!
Reference
https://dreambooth.github.io/
https://arxiv.org/pdf/2208.12242.pdf
https://analyticsindiamag.com/google-just-stepped-up-the-game-for-text-to-image-ai/






