
[가상생명연구팀 양승무 주임]
ChatGPT의 시대가 도래하고 있습니다. AI 업계를 비롯한 다양한 산업과 분야에서도 ChatGPT의 우수성과 실용성이 인정되어, 많은 기업들이 ChatGPT의 적용을 추진하고 있습니다. 이러한 추세는 OpenAI와 같은 주요 기업들 뿐만 아니라 Google, Meta와 같은 대규모 기업들도 생성형 AI 챗봇을 주도하는 역할을 맡고 있음을 보여줍니다.

이런 상황에서 기업들은 데이터 프라이버시와 효율적인 비용 지출을 위한 고심을 하고 있으며 해결책으로 모델의 현지화(한글화) 혹은 기업들의 고유 데이터를 활용한 자체 맞춤형 대형 언어 모델 (LLMs)의 개발을 적극적으로 검토하고 있습니다. 이러한 패러다임의 전환은 비단 언어모델 뿐 아니라 이미지, 음성생성 분야에도 적용이 될 것입니다. 이를 가속화하기 위해 몇 가지 foundation model(라마, 알파카, 비쿠냐 등)이 오픈 소스로 출시되었으며, 기업들의 요구 사항에 부합하는 맞춤형 언어 모델로 비즈니스를 강화할 수 있는 기회를 제공할 것입니다. 이번 글에서는 앞서 연구된 도메인 특화 모델을 살펴보고 이를 통해 얻을 수 있는 장점에 대해서 알아보겠습니다.


도메인 특화 모델에 대한 연구는 활발하게 진행되고 있으며 생물의학, 금융, 법학, 자연 과학 등의 분야에서 많은 발전이 이루어졌습니다. 특히 생물의학 분야는 BioASQ와 같은 질의응답 챌린지를 개최하는 등 기계학습 적용에 앞장서고 있습니다. 또한 지속적인 과학의 발전으로 매일 새로운 생물의학 논문이 발표되기 때문에 다량의 생물의학 데이터를 확보하기 용이합니다. 이를 활용하여 다양 생물의학 문헌에 대한 텍스트 마이닝과 지식 추출 등의 기법을 사용하면 새로운 약물, 임상 치료, 병리학 연구 등의 개발에 중요한 역할을 할 수 있음이 입증되었습니다. 널리 알려진 도메인 특화 모델로는 BioBERT와 PubmedBERT 등이 있습니다. 이 모델들은 해당 도메인의 데이터만을 학습에 사용하였는지, 아니면 범용적인 데이터을 학습에 사용하고 추가로 해당 도메인의 데이터를 사용하였는지에 따라 차이가 있지만 공통적으로 질의 응답, 개체명 인식, 관계 추출 등 주어진 정보에서 정답을 판별하는 자연어 이해 태스크에서 범용 목적의 모델보다 우수한 성능을 보였습니다.
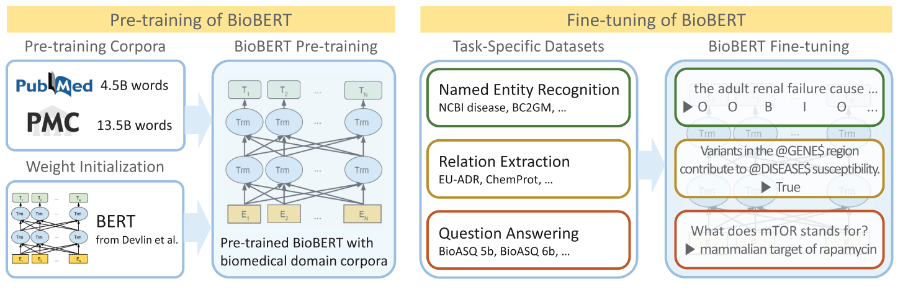
최근에는 판별 모델이 아닌 모델의 생성 능력으로 문제를 해결하고자 GPT 모델을 사용하는 연구도 진행되고 있습니다. PubMed 등에 수록된 논문을 GPT로 학습시킨 BioGPT는 기존의 도메인 특화 모델을 상회하는 성능을 보였다고 합니다. 이러한 도메인 특화 생성 모델은 데이터 증강기법에도 유용합니다. 최근에 발표된 Dr.LLama[4] 논문에서는 모델의 크기가 작더라도 도메인 특화 및 전문 지식이 반영된 언어 모델이 데이터 증강에 도움이 된다는 연구 결과가 소개되었습니다. 해당 연구에서는 전문 지식이 반영되지 않은 생성 모델이 생성한 문장으로 모델을 추가 학습시키면 오히려 성능이 저하되는 반면, 전문 지식이 반영된 모델이 생성한 문장으로 학습하면 성능이 향상되는 것을 확인하였다고 주장했습니다. 이러한 연구 결과들은 앞서 언급한 문제점들을 해결하기 위한 단서가 될 것입니다. 회사의 전문 지식이 반영된 자체적으로 학습한 언어 모델은 타 기업과 데이터를 공유하지 않고도 자체 리소스를 활용하여 기업의 데이터 프라이버시와 비용 효율성을 해결할 수 있을 것이기 때문입니다.

위의 이야기들을 종합했을 때, 조직들이 맞춤형 언어 모델을 구축하는 데 대한 관심이 증가함에 따라 통제, 데이터 개인 정보 보호 및 비용 효율성에 대한 중요성이 높아지고 있습니다. 도메인 특화 모델을 채택함으로써 기업은 성능 향상, 맞춤형 응답, 그리고 조직 내 여러 부서의 문제 해결 지원을 통한 원활한 업무 운영 등 다양한 장점을 얻을 수 있습니다. 게임 산업에 적용하여 예를 든다면, 서비스를 하면서 축적한 공략에 관한 데이터를 학습하여 업데이트에 따라 시시각각 변하는 캐릭터 육성법, 스토리 공략법에 대한 정보를 시의적절하게 생성해줄 수 있을 것입니다. 또한 신규 게임을 준비하는 부서에게 게임의 세계관 생성을 돕거나 홍보를 위한 2차 창작물(팬픽) 생성 등 자체적으로 보유한 IP 데이터로 학습된 맞춤형 언어모델을 도입함으로써 유저의 콘텐츠 소비를 직간접적으로 도울 수 있을 것입니다. 이러한 맞춤형 모델은 게임 용어, 전략, 플레이어 행동에 대한 깊은 이해를 갖추고 있어 게임의 플레이어 경험을 최적화하고 새로운 창의적인 요소를 추가하여 게임의 성공을 크게 향상시킬 수 있을 것입니다.
엄청난 기술들이 계속해서 등장하고 있지만, 결국 필요한 것은 고유한 데이터입니다. 언제나 그랬듯이 데이터를 준비하는 것에 집중하면 산적해있는 여러 비즈니스 문제를 해결할 수 있을 것이라 생각합니다.
Reference
[1] https://github.com/tatsu-lab/stanford_alpaca
[2] https://github.com/lm-sys/FastChat
[3] Lee, J., Yoon, W., Kim, S., Kim, D., Kim, S., So, C. H., & Kang, J. (2020). BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4), 1234-1240.
[4] Guo, Z., Wang, P., Wang, Y., & Yu, S. (2023). Dr. LLaMA: Improving Small Language Models in Domain-Specific QA via Generative Data Augmentation. arXiv preprint arXiv:2305.07804.






