인공지능의 발전은 우리의 삶에 큰 변화를 가져왔습니다. 특히 generative 모델은 이러한 변화의 중심에 서 있습니다. 디퓨전을 기반으로 한 생성 모델이 이미지, 오디오 생성 분야에 활용되고 있으며, 다양한 성과를 보여 주고 있습니다. 하지만 디퓨전 기반 생성 모델은 추론을 위한 연산 복잡도가 높기 때문에 추론 속도에 대한 고민이 있습니다. 최근 이러한 고민이 발전 하면서 One-step 생성이나 Conditional Flow Matching 과 같은 기술이 주목 받고 있습니다. 이러한 기술들은 기존 디퓨전과 유사한 생성 방법을 따르지만 작은 Number of Function Evaluation (NFE)로 우수한 성능을 보여주고 있습니다. 본 포스팅에서는 2023년 ICLR에서 Lipman 선생님이 발표하신 논문 Flow Matching for Generative Modeling의 내용인 Conditional Flow Matching에 대한 소개와 활용되고 있는 연구 분야에 대해서 이야기 하겠습니다.
Conditional Flow Matching (CFM) 이란?
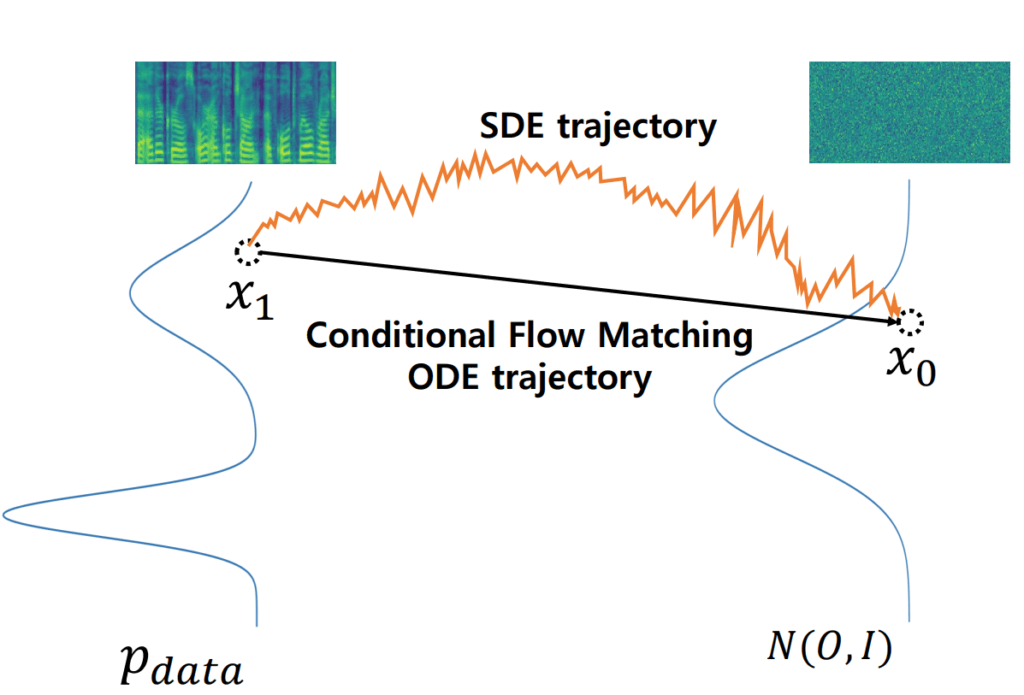
CFM은 초기 상태 X0를 목표 상태 X1 으로 이동 시키는 것을 목표로 하고 있습니다. 이러한 접근은 디퓨전 모델과 동일한 Score 기반 생성 모델을 따르고 있습니다. 다만 디퓨전 기반 모델과의 차이점은 X0 -> X1으로 변환 하기 위한 데이터의 이동 경로를 정의 하는데 있습니다. 디퓨전 기반 생성 모델의 경우 Forward와 Backward process를 정의 하는데 있어서 Stochastic Differential Equation (SDE) path를 따르고 있습니다. 반면 CFM 기반 생성 모델은 Ordinary Differential Equation (ODE) path를 따르고 있기 때문에 시간변수 t 에 대한 미분을 통해 이동경로를 정의 할 수 있습니다.
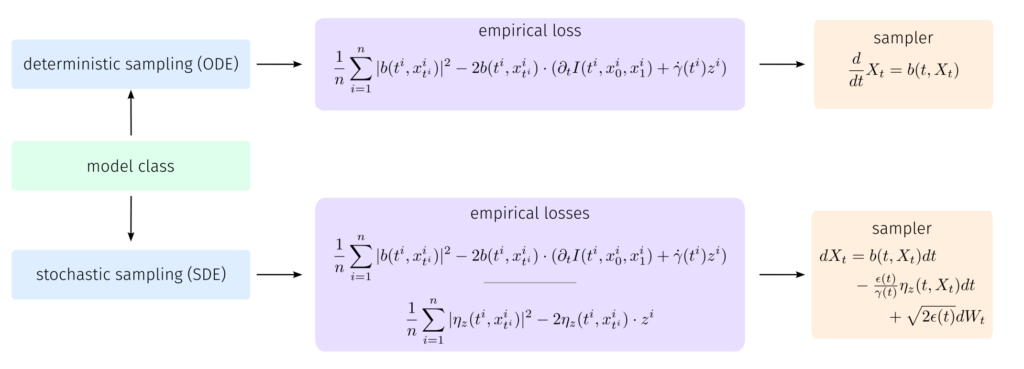
내용이 어렵나요? 그럼 좀 더 구체적으로 설명 드리겠습니다.
물체가 시간 변화에 따른 함수 F(t)로 움직인다고 가정해 보겠습니다. 이 물체가 현재 시간 t 에서 t+1로 움직일 때는 dF(t)/dt 라는 미분 정보를 통해 물제가 어떻게 움직일 수 있는지 알 수 있게 됩니다.
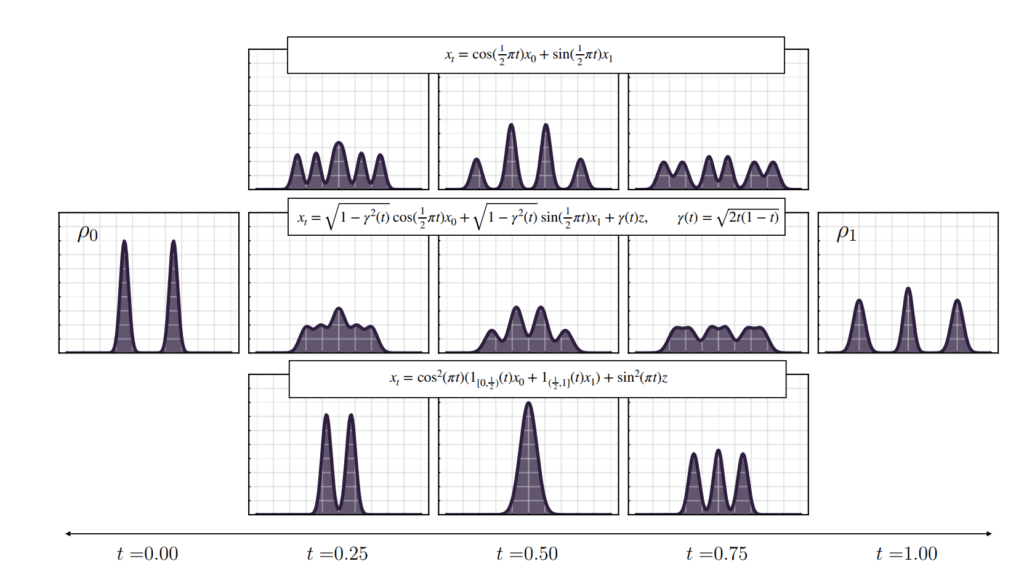
이러한 원리를 생성 모델에 적용해 보겠습니다. X0 와 X1 이 시간에 따른 미분 가능한 함수 F(t)로 정의가 될 수 있다면, 그리고 F(0) = X0 , F(1) = X1을 만족한다면 F(t)는 CFM의 path 활용 될 수 있습니다. 그리고 Neural Network를 통해 Xn=F(tn) 을 입력으로 받아서 F(tn)’ 를 추론 하도록 Supervised learning을 통한 직관적으로 모델 학습이 가능하며, ODE sampling을 통한 X0 -> X1 변환이 가능해집니다.
여기서 X0를 가우시간 분포 X1을 목표 이미지로 생각해 보면, Noise에서 Sampling을 통해 이미지를 생성하는 디퓨전과 유사하게 이미지를 생성 할 수 있게 됩니다.
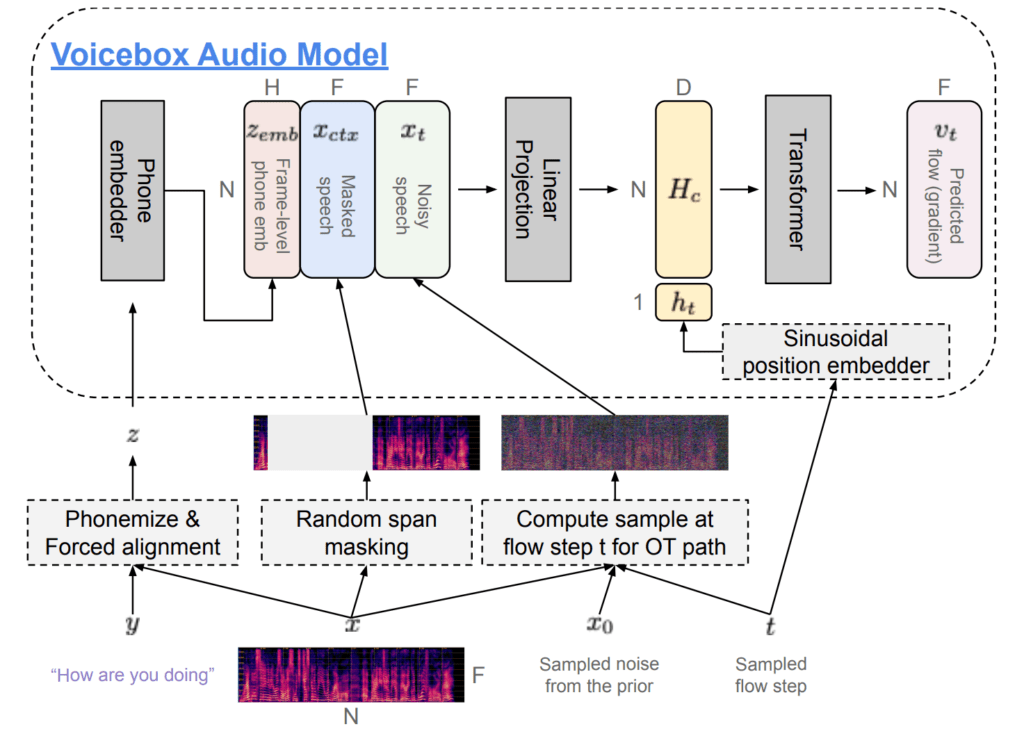
CFM의 음성 연구 활용
이러한 CFM은 고전적인 이미지 생성을 넘어 음성 합성 분야에도 많이 활용 되고 있습니다. META에서 발표된 Voice Box 의 경우 목표 화자가 정의 되어 있는 상황에서 Text embedding을 latent로 정의 하고, Transformer 기반 Masked prediction을 통해 CFM 모델을 학습 하고 있습니다. 이러한 CFM 기반 음성 합성 연구는 최근 큰 주목을 받고 있으며, 보다 우수한 합성 퀄리티와 경량화 연구가 진행되고 있습니다.