借助咳嗽声预测电晕19感染的AI技术
Corona 19尚未在全球范围内表现出平静的迹象。在麻省理工学院,我们学习了一种AI模型,该模型可以通过用手机记录的咳嗽声来检查是否存在Corona 19感染,并以此发表了方法论和实验结果。在实验结果中...
Corona 19尚未在全球范围内表现出平静的迹象。在麻省理工学院,我们学习了一种AI模型,该模型可以通过用手机记录的咳嗽声来检查是否存在Corona 19感染,并以此发表了方法论和实验结果。在实验结果中...
LipGAN是一种使用语音信号生成脸部图像的嘴唇形状的技术,当将其实际应用于视频时,在视觉伪像和运动自然度方面有些令人失望。为了改善这一点,鉴别器不是单个帧,而是多个连续的…
TensorflowTTS是基于Tensorflow 2的开源,它支持几种最新的TTS模型,例如Tacotron2,MelGan,FastSpeech等,终于开始支持Microsoft FastSpeech2。 FastSpeech2表现出与Transformer系列TTS类似的性能,但是学习时间却超过两倍。
麻省理工学院的Speech2Face是一项通过语音信号生成说话者面部的研究。但是,它不使用一种模型执行语音到面对面的转换,而是将现有研究的结果用于不同目的进行组合以产生令人印象深刻的结果。 (第一作者现在是...
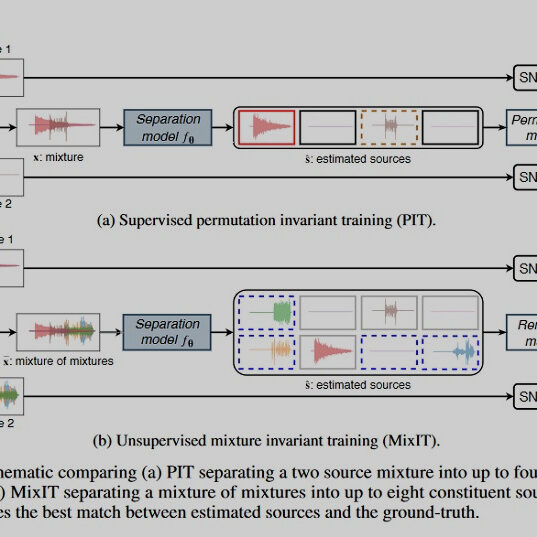
由Google推出的MixIT AI是一项技术,该技术从混合了多个声源的单声道音频中获得单独的声源。它可以看作是盲目的源分离任务,并且与现有技术不同,它具有在无监督(!)的情况下提供出色性能的功能。
在对53,000小时的未标记数据进行了表示训练之后,发布了Facebook的wav2vec 2.0的预训练模型,该模型成为热门话题,因为它创建了仅带有10分钟标记数据的语音识别器。表示模型没有微调,...