기침소리로 코로나19 감염여부를 예측하는 AI 기술
코로나19가 전세계적으로 아직 진정될 기미를 보이지 않고 있습니다. MIT에서는 핸드폰으로 녹음한 기침소리로부터 코로나19 감염 여부를 확인할 수 있는 AI 모델을 학습하였고, 이에 대한 방법론과 실험 결과를 논문으로 발표하였습니다. 실험 결과에…
코로나19가 전세계적으로 아직 진정될 기미를 보이지 않고 있습니다. MIT에서는 핸드폰으로 녹음한 기침소리로부터 코로나19 감염 여부를 확인할 수 있는 AI 모델을 학습하였고, 이에 대한 방법론과 실험 결과를 논문으로 발표하였습니다. 실험 결과에…
LipGAN은 음성 신호를 이용하여 얼굴 이미지의 입술 모양을 생성하는 기술인데, 실제로 동영상에 적용해보니 visual artifact나 움직임의 자연성 측면에서 다소 아쉬움이 있었습니다. 이를 개선하기 위해서 Discriminator에서 단일 frame이 아니라 복수개의 연속된…
특수 훈련을 받으면 입술 움직임만으로 무슨 말 하는지 알 수 있다고 하는 이야기를 들은 적이 있는데요, 링크글의 연구는 이것을 AI로 실현한 것입니다^^ Lip2Wav라고 불리는 이 기술은 이미지로부터 ConvNet을 이용하여 feature를…
Tacotron2, MelGan, FastSpeech등 여러 최신 TTS 모델을 지원하는 Tensorflow 2 기반의 오픈소스인 TensorflowTTS가 드디어 Microsoft FastSpeech2를 지원하기 시작했습니다. FastSpeech2는 Transformer 계열의 TTS와 유사한 성능을 보이지만 학습에 걸리는 시간이 2배 이상…
MIT의 Speech2Face는 음성신호로부터 화자의 얼굴을 생성해내는 연구입니다. 다만 하나의 모델로 speech to face transform을 수행하는 것이 아니며, 다른 목적의 기존 연구 결과들을 잘 조합하여 인상적인 결과를 만들어냅니다. (제1 저자는 현재…
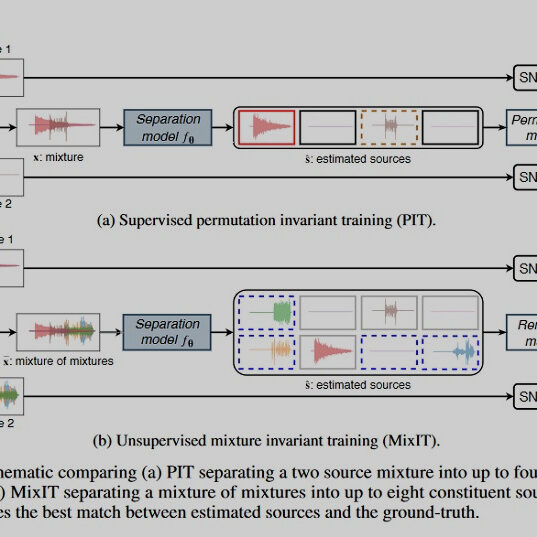
Google이 공개한 MixIT AI는 복수개 음원이 믹싱된 싱글 채널 오디오로부터 분리된 음원을 얻는 기술입니다. Blind source separation task라고 볼 수 있는데, 기존 기술들과는 달리 unsupervised(!)로 우수한 성능을 낸다는 특징이 있습니다.…
53,000시간의 라벨링 없는 데이터로 representation training을 한 후, 10분 분량의 라벨링 된 데이터만으로 음성인식기를 만들어낸다고 해서 화제가 되었던 Facebook의 wav2vec 2.0에 대한 pre-trained model이 공개가 되었습니다. Representation model에 no fine-tuning,…
인간의 감정 인지나 표현은 복합적인 것이 많은데 (예: 화내는 감정은 표정, 목소리, 언어에 모두 영향을 줌) 오디오-비디오가 함께 묶여 있으면서 감성 라벨링이 되어 있는 오픈 데이터셋을 하나 소개합니다. The Ryerson…