
[Prior Research Team Hyunwoo Choi]
In May, DeepMind published a reinforcement learning paper titled 'Reward is Enough'. The authors give examples of 'a squirrel trying to increase satiety' and 'a kitchen robot trying to keep clean', and if appropriate rewards are defined, various abilities related to intelligence (cognition, memory, planning, movement, etc.) Claimed to be able to use it naturally and make decisions.

People often learn the ability to judge situations and make decisions on their own through various trials and errors to achieve something. Because reinforcement learning itself resembles these human learning principles, this claim that an appropriate reward system will play a key role in achieving AGI has some justification. However, although it may have been due to the somewhat provocative (?) title, there were also several skeptical views such as 'It is an assertion that has no substance' and 'It is difficult to define a clear reward in real life problems'.
XLand: A New Reinforcement Learning Environment
In fact, Reward is Enough may have been attacked more because it was a claim that did not include concrete implementation results. As if conscious of this gaze, DeepMind recently announced the results of an experiment in a new reinforcement learning environment called XLand.
Currently, AI research is moving from a method of fine-tuning a pre-trained model to a desired task, to a few-shot or even zero-shot learning that secures performance with little data. Reinforcement learning, on the other hand, seemed to have the fatal drawback of not being able to utilize a pre-trained model to learn a new task and always having to re-learn it from scratch. Against this background, reinforcement learning can also be applied to new tasks by generalizing knowledge once acquired! That is the key result of this presentation. Obviously, if efficient learning for a new task is possible, it can be considered as a form very close to AGI.

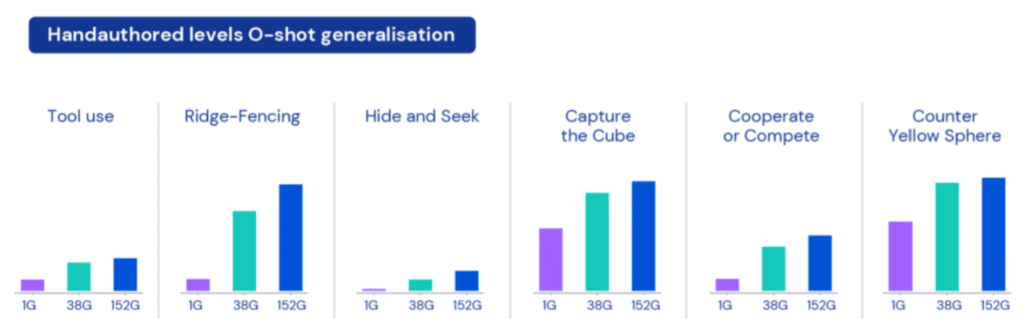
To demonstrate this, the authors built an XLand engine capable of rigid body physics simulations and automatically created various environments and targets for training agents. The goal may be for the agent to go "near the purple cube", or it may be given a more complex goal, such as "near the purple cube or put the yellow sphere on the red floor". There are also competing goals, such as hide-and-seek, “to see your opponent and not let them see you”.
Each agent has played approximately 700,000 unique games across 4,000 unique worlds within XLand, and has undergone 200 billion steps of learning across 3.4 million unique tasks. The results showed that even on new tasks that were not previously trained, significant performance could be obtained with only about 30 minutes of fine-tuning. On the other hand, the performance of the model trained from scratch was almost zero (though it is a natural result since the comparison target has trained 200 billion times).
The authors argue that the actions the agent takes to solve each problem may appear accidental, but are nevertheless consistent, indicating that the agent has a clear understanding of the reward system.
Can reinforcement learning become AGI?
As mentioned above, the authors showed the potential that pretrained reinforcement learning models can quickly adapt to a variety of novel tasks. However, it may be a bit difficult to break through the existing critical views that it has only greatly simplified the real world problem.
The authors also introduced a few examples of failures that were not learned well, which is quite interesting. First, if a crack (trap) that did not appear in the pre-learning appeared, the agent could not assume that it could fall into the trap, so it continued to fail to reach the goal. It can solve the problem of going to the upper floor by making a slope using surrounding objects, but it cannot solve the problem of making multiple slopes consecutively (this part is definitely because the dimension of trial and error is too large to solve, the limitation of reinforcement learning appears. Seems to). In addition, when the goals of the two agents are different, the other agent's goals were not understood, so they could not achieve their own goals.
Even though reinforcement learning is a technique that imitates human learning patterns, there seem to be many curious parts about how humans can easily solve problems that are difficult for AI to solve. Even in a simulation environment where the agent has few action options, it seems that the limitations of AGI are still clear in that it has been trained 200 billion times.
Still, you might think that we've made a lot of progress just by being the first (perhaps) to show how flexible reinforcement learning models can be used. I am very curious to see if further research can find clues to solve the failure cases 🙂
References
- https://deepmind.com/research/publications/2021/Reward-is-Enough
- https://deepmind.com/blog/article/generally-capable-agents-emerge-from-open-ended-play






