
썸네일 출처: https://cliparts.zone/clipart/39255
[융합연구팀 전동준]
“어제 홈스파 3편 보고 왔어요” 라고 누군가가 말한다면 여러가지 반응이 나올 수 있습니다. ‘홈스파’가 마블에서 제작한 스파이더맨 영화 시리즈의 약칭인 것을 모른다면 인터넷에 ‘홈스파’ 라는 키워드를 검색하여 무엇인지 찾아볼 수도 있고, 스파이더맨 시리즈를 본 사람이라면 이전에 본 스파이더맨 시리즈들에 나오는 빌런들을 기억하면서 대화를 이어나갈 수도 있습니다.
사람의 기억 구성
뇌가 말하는데 평균 0.6초가 걸린다고 합니다. 미국 샌디에이고 캘리포니아대와 하버드대 연구진의 연구한 사실에 의하면 뇌가 외부 자극에 반응해 단어를 고르는 데 0.2초, 문법에 맞추는데 0.12초, 발음을 결정하는데 0.13초, 입에서 소리는 내는데 0.15초가 걸려서 도합 0.6초가 걸린다고 합니다. 여기서 만약 과거의 일이나 내가 알고 있는 지식에 기반한 답변을 할 때에는 더 많은 과정이 필요할 것 같습니다.
사람의 기억이 어디에 저장되는가를 규명하는 것은 오래된 문제였습니다. 최근의 연구는 뇌의 무수히 많은 뉴런과 이들 사이의 시냅스 연결로 구성된 복잡한 신경 네트워크에서 기억을 인코딩한다고 규명되었다고 합니다. (간단하게 뇌의 어딘가에 기억이 인코딩 된다라고 생각하겠습니다…) 우리의 뇌에 없는 정보라면 외부에서 정보를 가져와야 합니다. 현대는 어디서든 접근할 수 있는 인터넷, 스마트폰이 외부 정보를 가져오는데 큰 도움을 주고 있습니다.
AI의 기억 구성
현재의 딥러닝 AI 모델들은 사람 뇌의 구조를 모방하는 학습 방법을 택하고 있으며, 자연히 더 많은 데이터를 넣어서 기억하게 만들면 더 좋은 성능의 AI를 만들 수 있다고 생각했습니다. 하지만 많은 학습 파라미터를 가진 AI 모델들은 새로운 기억 정보를 학습하는데에 어려움이 있습니다. 사람도 새로운 정보를 기억하는데 물론 힘들지만, 추론과 구조화의 힘으로 새로운 기억 정보를 효과적으로 기억합니다. 그러나 AI 모델에게 새로운 정보를 계속하여 업데이트 해주는 것은 거대 모델들에게 힘든 일이었고, 많은 리소스가 필요했습니다.
그래서 최근의 연구들은 사람과 비슷한 프로세스를 통하여, 기억할 것은 기억하고, 외부의 정보가 필요한 지식이면 외부 지식을 이용한 방식을 통해 학습하는 접근을 택했습니다. DeepMind의 The Retrieval-Enhanced Transformer(RETRO)와 그 다음으로 나온 OpenAI의 WebGPT, 그리고 이전 Facebook Research에서 발표한 Blender Bot 2.0 는 무조건 많은 데이터를 학습하는 것이 아닌 외부정보를 적절히 사용하는 방식을 택하고 있습니다.
DeepMind – RETRO
이번 달 초에 DeepMind에서는 대규모 언어모델(LM)인 Gopher를 발표하면서 인터넷 검색을 통해 리소스를 절약하면서 학습하고 모델의 산출물을 쉽게 추적할 수 있는 모델인 RETRO도 같이 발표했습니다. RETRO는 The Retrieval-Enhanced Transformer의 약자로 내부의 검색 데이터베이스를 구축하고(웹, 책, 뉴스, 위키피디아, 깃허브등) 언어모델을 학습할 때 입력 데이터를 데이터베이스를 통해 질의(Query)함으로써 텍스트 생성이나, 이 텍스트가 어디에서 왔는지 등의 예측을 쉽게 해주는 메커니즘입니다.
예를 들어 밑에 구조도에서 처럼 “2021년의 여자 US 테니스 오픈 우승자가 누구야?” 라는 질문에 대해서 데이터베이스를 통해 이 질문과 관련된 문서들을 검색하고 이 문서를 인코딩하여 학습 아웃풋을 만드는데 이용하는 구조입니다. 코드등이 공개되어 있진 않지만 다양한 자연어 벤치마크에서 뛰어난 성능을 보인다고 합니다.
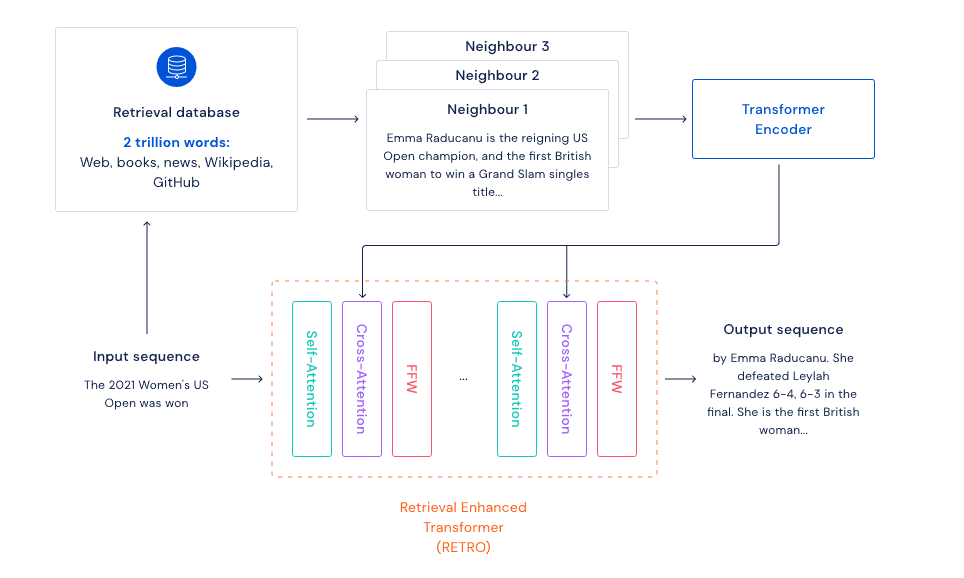
https://deepmind.com/blog/article/language-modelling-at-scale
OpenAI – WebGPT
DeepMind가 GPT-3보다 큰 파라미터의 모델인 Gopher와 윤리모델, RETRO등을 발표하면서 OpenAI도 바로 이어서 웹 검색을 통한 GPT-3 파인튜닝 방법과 성능을 공개했습니다. 인터넷 Bing 검색 API를 통해서 질문에 대한 검색결과를 얻고, 이를 GPT-3의 정확도를 올리기 위한 방법으로 사용합니다.
수에즈 운하가 왜 막혔는지에 대한 질문에 대해서 WebGPT는 웹 검색을 통해서 위키피디아의 ‘2021 Suez Canal obstruction’ 문서에 대한 정보를 가져오고 이를 텍스트 생성에 사용합니다. 이는 지식을 요구하는 질문에 대해서 엉뚱하게 답할 수 있는 GPT의 한계를 극복하는 방법이 되고 있습니다.

https://openai.com/blog/improving-factual-accuracy/
Meta AI – Blender Bot 2.0
최근 사명이 바뀐 Meta가 7월에 발표한 Blender Bot 2.0도 인터넷 검색을 이용한 Open Domain의 대화 생성모델입니다. 기존 Blender Bot 1.0이 정적인 정보만을 이용하여 답변하는 한계를 극복하고자 대화 히스토리 정보 인코딩, 메모리 정보 인코딩, 인터넷 검색정보 인코딩 정보 합하여 이를 답변 생성에 사용합니다. 실제 세상의 지식을 사용하는 능력을 통하여 실제 사람들이 테스트한 결과 대화를 매끄럽게 이어갈 수 있고 성능이 좋아졌다고 평가되고 있습니다.

https://ai.facebook.com/blog/blender-bot-2-an-open-source-chatbot-that-builds-long-term-memory-and-searches-the-internet
AI의 기억을 사람의 기억으로

https://movie.naver.com/movie/bi/mi/photoView.naver?code=104816&imageNid=6451997#tab
최근 외부 정보를 사용한다는 거대 딥러닝 모델들의 접근 방식은 기존의 정적인 정보 업데이트를 보완하는 효과적인 방식으로 보입니다. 사람도 이런 방식으로 정보를 기억하고 이용할 수 있을까요? 영화 ‘트랜센던스’ 에서는 뇌가 인터넷으로 업로드가 되어서 연결된 모든 정보를 활용하는 힘을 가지는 주인공이 나옵니다. 이 주인공은 인터넷의 모든 정보를 이용할 수 있기 때문에 전지전능한 능력을 가지게 됩니다.
우리는 모르는게 있으면 다른 사람에게 물어보거나 구글링을 합니다. 새로운 정보를 어떤 수단을 통해서 얻고 자기에게 각인시킵니다. 일론 머스크가 ‘인간 뇌와 컴퓨터의 결합’을 목표로 설립한 뉴럴링크는 궁극적으로 사람 뇌에 칩을 이식할 것을 계획하고 있습니다. 이런 컴퓨터 형태의 칩을 이용하면 기억에 대한 한계를 극복할 수 있을까요? 매일 휴대폰과 차키를 어디에 두었는지 까먹지 않고, 새로 나온 스파이더맨 영화의 정보들도 실시간으로 얻을 수 있는 사람이 될 수 있을까요?









