
[생성지능개발팀 정우석]
진부한 이야기이지만 AI 연구에 있어서 데이터의 중요성은 아무리 강조해도 지나치지 않습니다. 수많은 학교, 연구기관이나 기업에서는 앞다퉈 기술력 자랑과 연구 성과를 위해 다양한 분야의 AI 관련 논문들을 발표하고 있습니다. 하지만 연구하는 입장에서보면 AI 모델과 다양한 알고리즘들이 발표되고 있지만 이에 비해 이를 테스트하고 훈련할 연구용 데이터들은 엄청 한정되어 있고 대부분 수년전에 발표된 데이터들을 아직까지도 그대로 사용하고 있는 입장입니다.
당연하게도 기업에서는 AI모델보다는 실제 데이터들을 더 중요하게 생각하고 있고 대부분 공개하지 않고 있습니다.기업에 속해있지 않거나 데이터를 자유롭게 확보할수 없는 가난한(?) AI 연구자라면 새로운 분야에 AI를 적용하려는 연구를 하려고 해도 실제 연구용 데이터를 확보하기 까지는 너무 험난하다고 할수 있습니다.
AI연구자에게 데이터만 제공해주면 어떤 모델이든지 만들어 줄수 있다고 하지만 정작 데이터를 구하고 학습할수 있게 데이터를 레이블링 하는 작업은 많은 비용이 들고 시간이 오래 걸리는 작업입니다. 이에 계속해서 현실에서 실제 생성되고 수집된 데이터가 아니라 AI를 활용해 생성된 합성데이터의 유용성이 점차 커지고 있는 상황입니다.
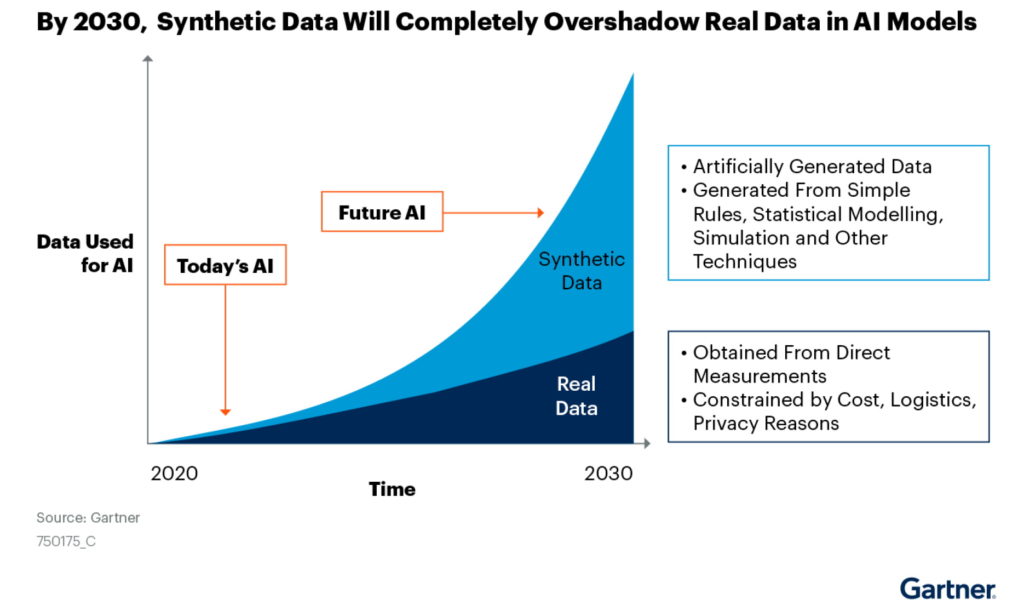
시장조사 회사인 가트너의 예측에 따르면 2024년 까지 AI 및 분석 프로젝트 개발에 사용되는 데이터의 60%가 합성으로 생성될 전망이라고 합니다. 합성 데이터 생성 시장은 2021년에 약 1억1000만 달러였고, 그랜드 뷰 리서치는 2030년까지 AI 학습 데이터셋 시장이 86억 달러 (약 11조1000억원)이상에 달할것으로 분석했습니다. 아마도 점차적으로 계속 합성데이터 사용비율은 늘어날것이고 최후에 실제 리얼 데이터는 고객에게 전달하기 마지막 모델에서만 튜닝용으로 사용할지도 모릅니다. (최종적으로는 그것도 필요없을수도…)
이미 많은 오픈된 API를 사용하여 다양한 분야에서 음성, 텍스트, 이미지등 합성데이터를 만들어 연구용으로 사용하고 있는데 이미지의 경우 현재 DALL-E를 비롯하여 많은 이미지 생성모델들도 쏟아져 나오고 있습니다. 이처럼 생성모델들이 계속 고도화 되고 진짜 같은 ‘가짜’ 데이터를 생성할수 있다면 합성데이터만으로 충분히 좋은 상업적인 모델들을 만들수 있을것입니다. 모든 분야에 적용가능한 이미지를 생성하는건 역시 데이터 문제지만…다만 합성데이터는 생성하는 사용자의 입맛에 맛게 생성할수 있기 때문에 데이터를 생성하는 입장에서는 많은 고민이 필요할것입니다. (이것도 역시 자동화 할수 있을것입니다.)
AutoML처럼 빅데이터 분석을 통한 ML 모델 구축 뿐만 아니라 생성 모델 만드는것도 자동화 할수 있다면 AI가 스스로 학습을 위한 데이터를 생성하고 모델을 만들고 진정한 AI 자동화가 이루어질수도 있을것입니다. 끊임없이 스스로 모델을 생성하는…
엊그제 smilegate.ai에 올라온 “인공지능은 우리를 어디까지 대체할 것인가?“라는 글을 보고 AI가 발전됨에 따라 일자리가 점차 사라지고 대체된다는 관점에서 정작 가장빨리 대체될수 있는건 AI를 연구개발하는 AI개발자들이 일순위 일수도 있을거라고 생각되었습니다. 결국 소수의 AI 연구자들만 살아남고 AI개발을 잘모르는 해당 도메인의 전문가들이 AI모델들을 만들게 될것입니다.
아래는 다양한 이미지 생성기 입니다.
달리2 (DALL-E 2)
딥 드림 제너레이터 (Deep Dream Generator)
아트브리더 (Artbreeder)
빅 슬립 (Big Sleep)
나이트카페 (NightCafe)
딥AI (DeepAI)
스타리 AI (StarryAI)
포터 (Fortor)
런웨이 ML (Runway ML)
웜보 드림 (WONBO Dream)
References
[1] “달리만 있나?” AI아트 생성기 10선 https://www.aitimes.com/news/articleView.html?idxno=145252






