[분석지능개발팀 박효주]
ML 모델의 Lifecycle은 연구 및 테스트를 진행하는 Research 단계와 실제 서비스화하는 Production 단계로 나눌 수 있습니다. Research 단계에서는 문제 정의부터 모델 선정, 성능을 높이기 위한 다양한 실험 등을 진행하게 됩니다. 이때는 당장의 서비스화는 고려하지 않고 모델 성능을 최대한 높일 수 있는 방법만을 고민합니다. Production 단계에서는 가장 높은 성능의 모델이 학습된 환경을 관리하고 Versioning해서 배포 환경에 그대로 적용될 수 있도록 합니다. 이때는 모델을 최대한 빠르고 안정적으로 배포하는 방법만을 고민합니다.
두 단계는 서로 목표가 다르기 때문에 각자의 역할도 다릅니다. Research 단계는 ML Researcher(혹은 Data Scientist)가, Production 단계는 ML Engineer가 진행하게 됩니다. 따라서 ML Researcher가 ML Engineer에게 모델을 전달하는 과정이 자연스럽게 이루어지는 것이 물 흐르듯 자연스러운 모델 Lifecycle 관리의 핵심입니다. 지금까지 설명한 이 Lifecycle을 MLflow를 이용해 관리할 수 있습니다.
MLflow는 ML 모델의 Lifecycle을 관리하는 플랫폼입니다. 내부에는 Tracking, Projects, Models, Model Registry 4가지 컴포넌트로 구성되어 있습니다.
Tracking
Tracking은 ML Researcher가 진행한 다양한 실험의 parameters, metrics, artifacts 등을 로깅하기 위한 API 및 UI입니다. ML Researcher는 기존 실험 코드에 단 2줄(run, log_model)만 추가해도 위에서 언급한 정보들을 전부 로깅할 수 있으며, 코드를 추가해서 커스텀한 로깅도 가능합니다.

Tracking은 로컬 환경에서 구축하는 방법부터 서버와 DB를 구축하는 방법까지 6가지 시나리오로 나눌 수 있습니다. 자세한 내용은 공식 문서의 “How Runs and Artifacts are Recorded” 부분(https://www.mlflow.org/docs/latest/tracking.html#how-runs-and-artifacts-are-recorded)을 참고바라며, ML Researcher와 ML Engineer 간의 원활한 협업을 위해서는 최소 공식 문서에 있는 시나리오4 이상의 아키텍처 구성을 추천합니다.
Projects
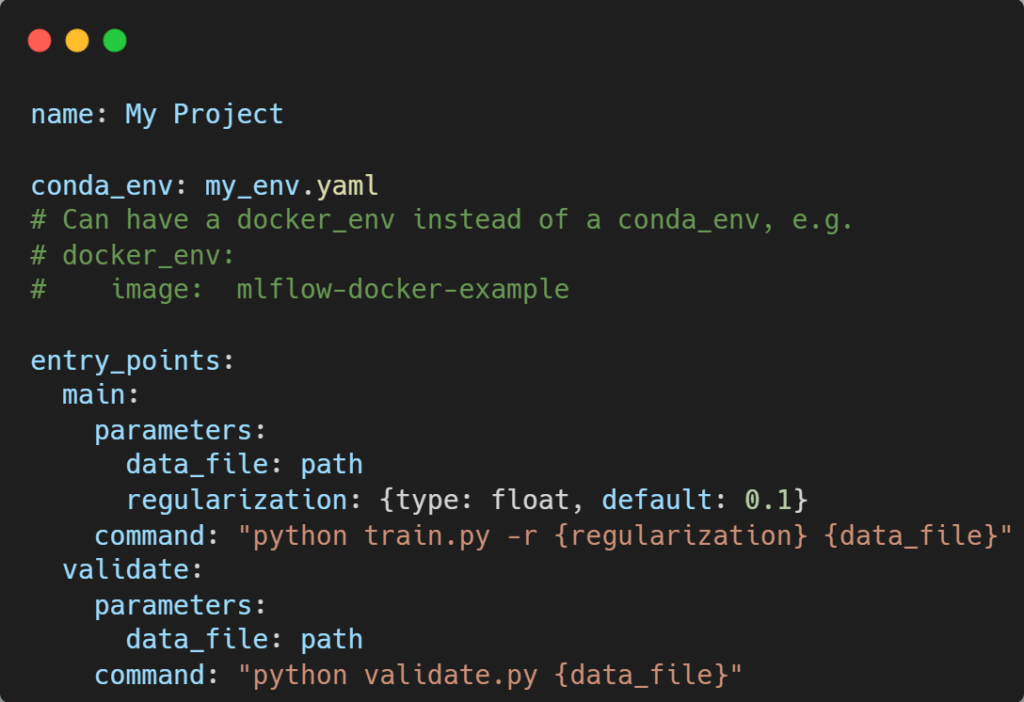
Projects는 코드를 재사용 및 재현 가능한 방식으로 패키징하기 위한 포맷입니다. Dockerfile과 유사한 형태의 MLproject 파일에 python 버전, 패키지, 도커 컨테이너 등의 정보를 입력하고 실행할 커맨드를 저장합니다. 이때 parameters 정보를 외부에서 입력 가능하도록 설정도 가능합니다. Python 패키지는 기본적으로 conda가 적용되지만 pip도 사용 가능합니다. 이 MLproject를 이용해서 하나의 project 단위로 관리가 가능해집니다.
Models
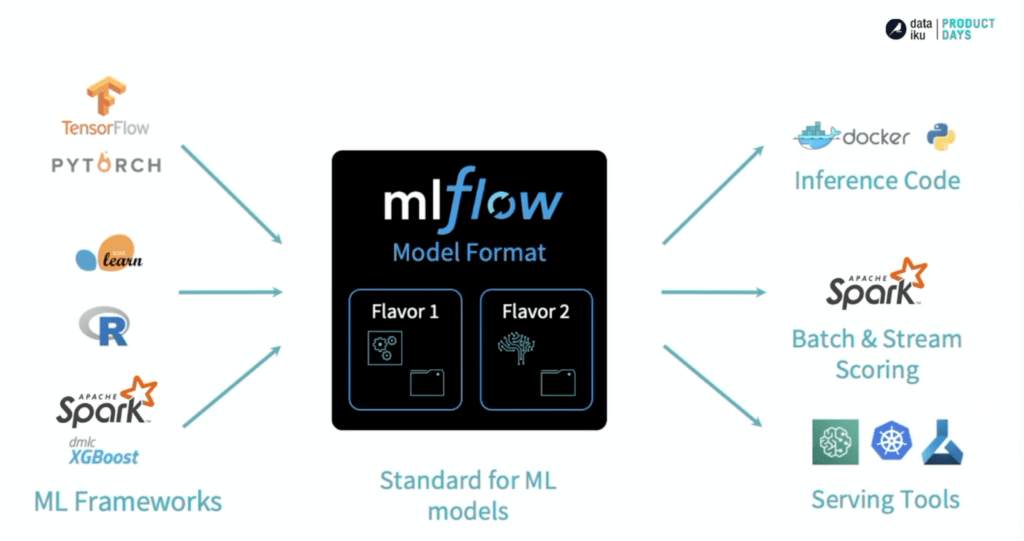
Models는 다양한 프레임워크로 학습한 모델을 패키징하기 위한 표준 포맷입니다. ML Researcher 마다 선호하는프레임워크가 다를 수 있는데, 표준 포맷으로 패키징함으로써 다양한 프레임워크로 학습된 모델을 동일한 MLflow 코드를 사용해서 배포할 수 있게 됩니다.
Model Registry
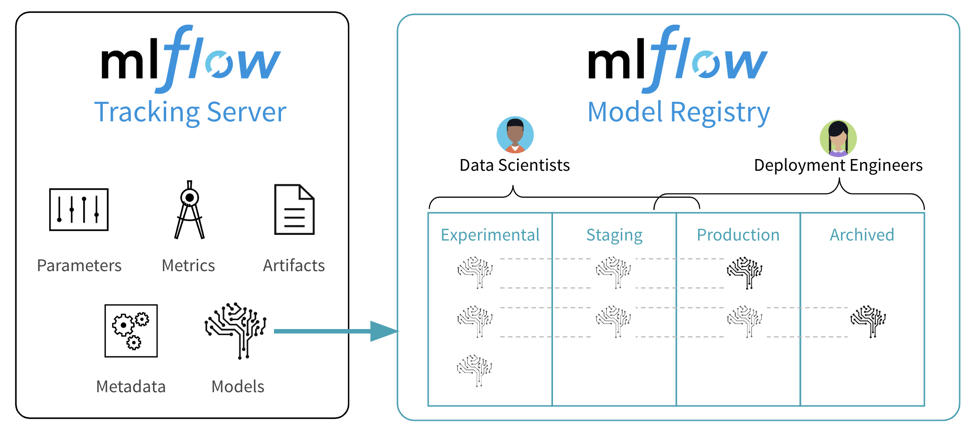
Model Registry는 모델의 Lifecycle 관리를 위한 중앙 집중식 모델 저장소입니다. 앞서 실험을 통해 학습된 모델을 등록하고 각 모델의 버전과 Stage(Production, Staging, Archived) 정보 등을 관리합니다. 이를 통해 모델 서빙 프레임워크에서는 Production 모델만 바라볼 수 있게 되고, Staging을 통해 모델을 배포하기 전에 A/B 테스트를 거쳐 Production 모델로 변경할 수 있게 됩니다. 이 과정이 ML Researcher가 실험 결과 모델을 Staging으로 올리면 ML Engineer가 A/B 테스트를 거쳐 Production으로 배포하는 과정이 됩니다.
ML 모델의 Lifecycle을 원활하게 운영하기 위해서는 ML Researcher와 ML Engineer의 원활한 협업이 필수입니다. 이를 위해 MLflow와 같은 ML Lifecycle 관리 플랫폼을 적극 활용할 필요가 있습니다.
Reference
- https://github.com/mlflow/mlflow/
- https://www.mlflow.org/docs/latest/concepts.html
- https://www.mlflow.org/docs/latest/tracking.html#how-runs-and-artifacts-are-recorded
- https://www.databricks.com/blog/2019/10/17/introducing-the-mlflow-model-registry.html
- https://blog.dataiku.com/introducing-mlflow-saved-models






