
[Interactive AI 기술팀 김윤혜]
RAG(Retrieval-Augmented Generation, 검색 증강 생성) 파이프라인은 대규모 언어 모델(LLM)의 한계를 보완하기 위해 외부 지식을 활용하여 보다 정확하고 관련성 높은 응답을 생성하는 기술입니다. 그러나 이러한 파이프라인의 성능을 객관적으로 평가하기란 쉽지 않은 일입니다. 이번 글에서는 이에 부응하여 등장한 RAG 파이프라인 평가 프레임워크 중 하나인 RAGAS(Retrieval-Augmented Generation Assessment)에 대해 알아보겠습니다.
RAGAS란?
RAGAS는 RAG 파이프라인의 정량적 평가를 지원하는 오픈 소스 프레임워크입니다. 이 프레임워크는 단순한 성능 평가를 넘어, 시스템의 각 구성 요소를 세밀히 분석할 수 있도록 설계되었습니다. 이를 통해 개발자는 문제의 원인을 빠르게 파악하고, 시스템을 최적화할 수 있습니다.
RAGAS Metrics
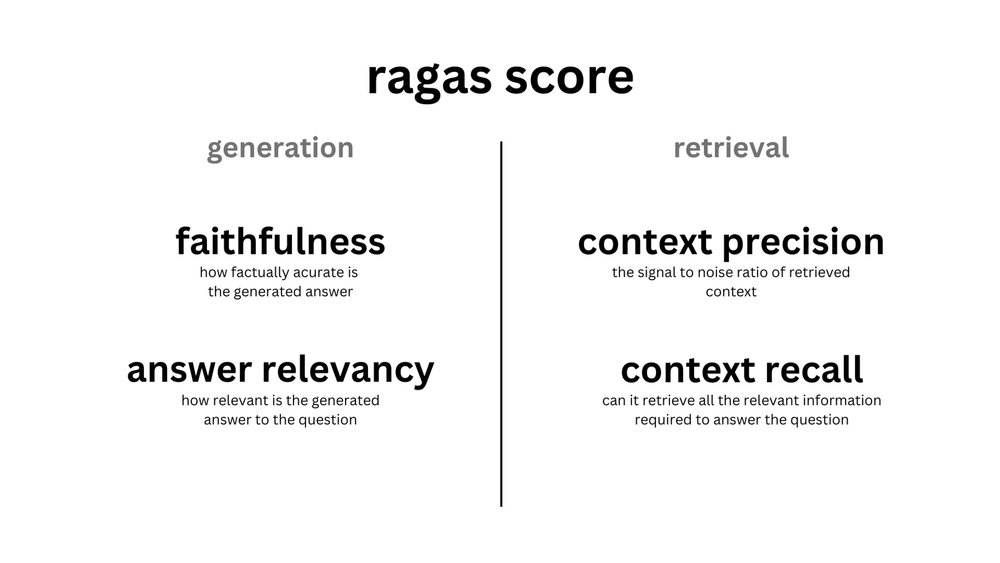
RAGAS는 RAG 파이프라인의 성능을 다각도로 평가하기 위해 여러 핵심 지표를 제공합니다. 주요 지표는 다음과 같습니다:
- Faithfulness(충실성): 생성된 답변이 주어진 컨텍스트에 얼마나 충실한지를 평가합니다. 즉, 답변이 컨텍스트에 기반하여 정확한 정보를 제공하는지를 측정합니다.
- Answer Relevancy(답변 관련성): 생성된 답변이 주어진 질문과 얼마나 관련성이 있는지를 평가합니다. 질문에 대한 명확하고 적절한 답변을 제공하는지를 측정합니다.
- Context Precision(컨텍스트 정밀도): 질문에 대한 컨텍스트 정보를 검색하여 가져온 컨텍스트 중, 질문에 대한 답변과 관련 있는 문서가 얼마나 상위에 랭크되어 있는지를 평가합니다. 즉, 검색된 정보의 정확도를 측정합니다.
- Context Recall(컨텍스트 재현율): 질문에 대한 답변을 생성하는 데 필요한 컨텍스트 정보를 검색할 수 있는지를 평가합니다. 즉, 필요한 정보를 얼마나 잘 찾아내는지를 측정합니다.
각 지표의 개념과 계산 방법을 더 자세히 알아봅시다.
Faithfulness
- 주어진 문맥을 얼마나 잘 반영하여 답변을 생성하였는지 평가.
- 점수 범위: 0~1 (1에 가까울수록 좋음.)
- context에서 답변에 대한 claims를 유추 가능할 수록 높은 점수를 부여.
Calculation
Step1. 생성된 답변으로부터 statements를 추출함. (llm 활용)
Step2. 추출한 statements가 주어진 context에서 추론될 수 있는지 여부를 판별함. (llm 활용)

Answer Relevancy
- 생성된 답변이 질문에 얼마나 잘 부합하는지 평가
- 점수 범위: -1~1 (1에 가까울수록 좋음)
- 생성된 답변을 기반으로 생성한 질문과 원래 질문의 cosine 유사도를 활용함.
- answer과 context만으로 question을 재구성할 수 있다는 개념을 활용한 방식.
Calculation
Step1. 컨텍스트를 기반으로 생성된 답변에 대한 질문을 생성함. (Reverse-engineer, llm 활용)
Step2. 실제 질문과 생성 질문 사이의 cosine similarity를 연산함.
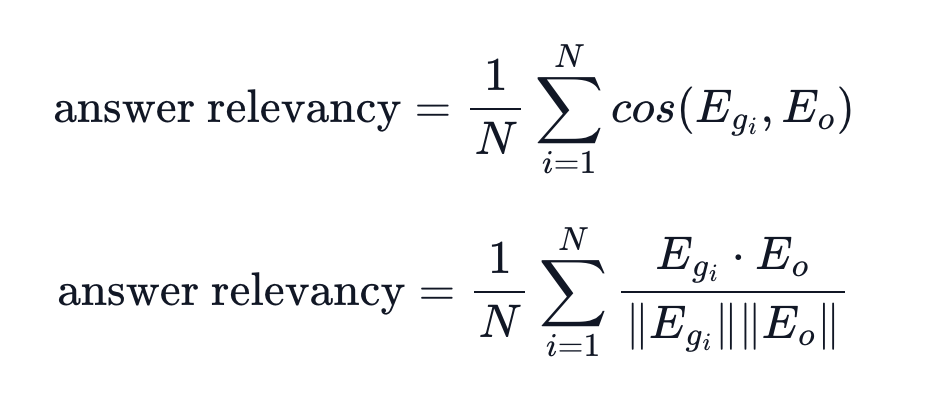
Context Precision
- 검색된 각 k개의 context가 question, ground truth와 연관이 있는지 평가.
- 점수 범위: 0~1 (1에 가까울수록 좋음)
- 검색 결과와 유효성을 기반으로 precision을 계산함.
Calculation
Step1. 검색된 k개의 context(chunk)가 question, ground truth와 연관이 있는지 판별. (llm 활용)
Step2. 각 context에 대한 precision 계산
Step3. precision의 평균을 구함

Context Recall
- 검색된 context가 ground truth와 얼마나 잘 일치하는지 평가.
- 점수 범위: 0~1 (1에 가까울수록 좋음)
- ground truth의 각 claim이 검색된 context와 얼마나 일치하는지 계산함.
Calculation
Step1. ground truth를 독립된 statements로 분리함.
Step2. 각 statements의 정보를 검색된 contexts에서 찾을 수 있는지 판별함.
Step3. step2의 결과를 기반으로 recall을 계산함.
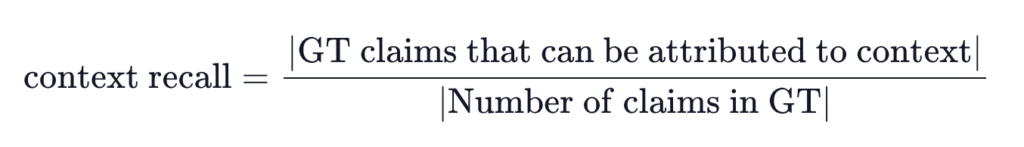
실습: RAGAS로 RAG 평가해보기
실제로 Streamlit을 활용한 간단한 Demo를 만들어 RAGAS 평가를 해보았습니다.
1. 평가 데이터셋 입력
우선 평가 데이터셋을 입력합니다. 본인은 직접 gpt-4o를 통해 생성하고 manual 정제한 데이터셋을 활용했습니다.
평가 데이터셋에는 ‘question’, ‘ground_truth’ 컬럼이 존재해야 합니다.
- question: 사용자 입력에 해당하는 질문
- ground_truth: 질문에 대응되는 정답
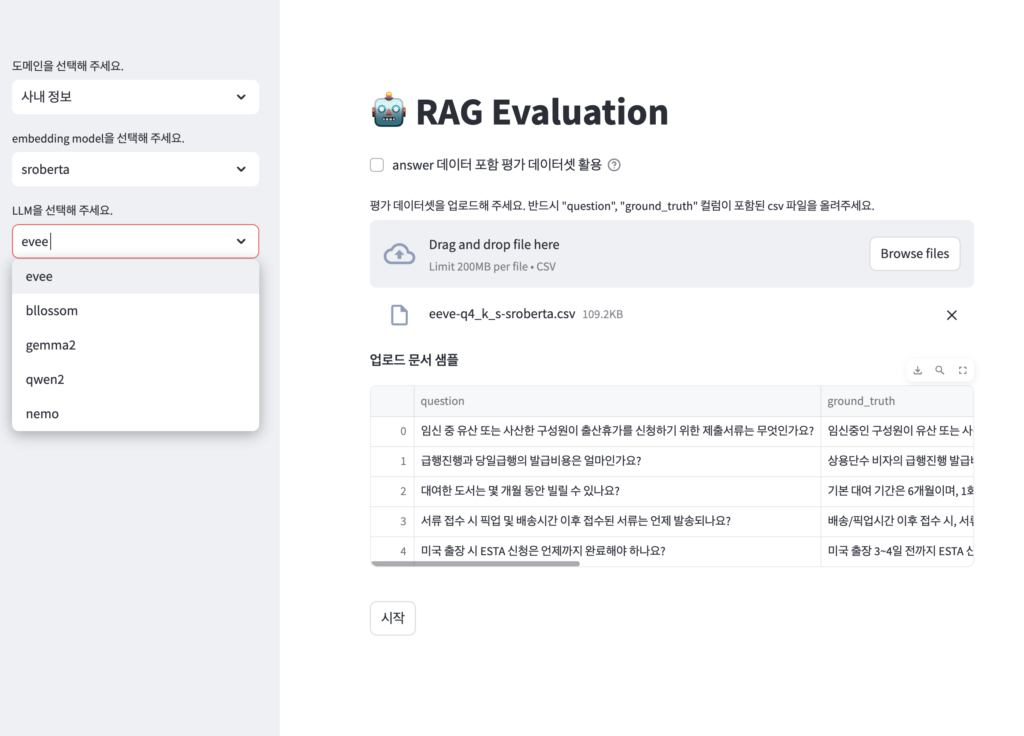
2. 모델 선택
평가하고 싶은 RAG 파이프라인의 LLM(생성)과 embedding model(검색)을 선택합니다.
3. RAGAS 평가 실행
ragas 평가 결과 확인

+) LangSmith를 활용한 평가 모니터링
위와 같은 정량 점수가 어떻게 산정됐는지 세세하게 확인할 수 있도록 RAGAS는 LangSmith 연동 기능도 제공하고 있습니다.
각 metrics을 계산할 때 사용된 모델, 프롬프트, output, 토큰 수 및 비용, latency 등을 아주 자세히 확인할 수 있습니다.

마무리
RAG 파이프라인은 검색과 생성이라는 두 축이 결합된 복잡한 시스템입니다. 이처럼 다층적인 구조에서는 각 단계의 성능을 세밀히 평가하고 개선하기 위한 정량적 평가 프레임워크가 필수적입니다.
객관적인 지표와 데이터를 바탕으로 파이프라인의 강점과 약점을 파악하면, 단순히 문제를 진단하는 데 그치지 않고 시스템의 전반적인 품질을 지속적으로 향상시킬 수 있습니다. 이는 단순한 결과의 정확성을 넘어, 신뢰성과 사용자 경험을 모두 향상시키는 데 핵심적인 역할을 합니다.
결국, 정량적 평가 프레임워크는 AI 시스템의 성능을 평가하고 최적화하는 데 있어 없어서는 안 될 도구입니다. 이를 통해 복잡한 RAG 시스템에서도 데이터 기반의 발전이 가능하며, 보다 견고하고 효율적인 AI 솔루션을 구축할 수 있습니다.
Reference
- https://github.com/explodinggradients/ragas






