Text-to-SQL is a task that automatically converts natural language into SQL. The post I shared at the bottom was written by Aerin Kim of Microsoft, and it is well organized about Text-to-SQL. Considering that a lot of data in the world is built as a relational database, and SQL is the standard language used to acquire information from this database, it is said that if Text-to-SQL is perfected, many fields of application can be made. Can be predicted easily.
First, the dataset used in the study is WikiSQL, which was built by SalesForce, a CRM company, using Amazon Mechanical Turk. (Attach the link at the bottom)

Early studies using this dataset are based on the seq2seq model used in various natural language “transformation” studies. To take an analogy, it's a technique that "translates" from human language to the language of SQL. Relatedly, SalesForce published a paper titled Seq2SQL. (Attach the link at the bottom)
databases. However, the ability for users to retrieve facts from a database is
limited due to a lack of understanding of query languages such as SQL. We
propose Seq2SQL, a deep neural network for translating natural language
quest…
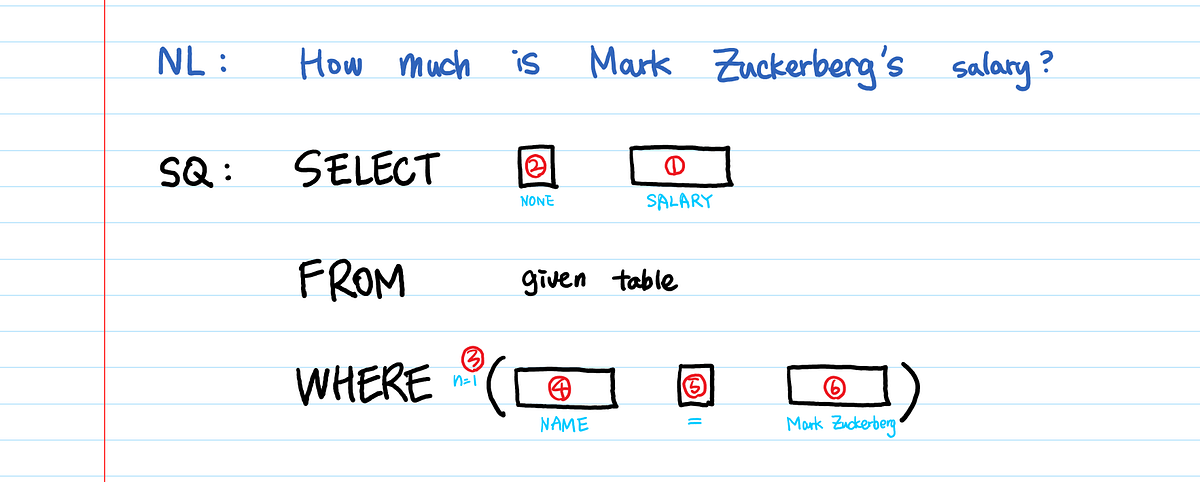
The paper above was published in 2017, and the current SOTA is a classification model, not a natural language transformation model. In other words, it uses a method of predicting the arguments of each phrase (SELECT, FROM, WHERE) that can appear in the SQL statement. In the shared article, we classified SQL statements into a total of 6 types (SELECT, AGGREGATION, number of WHERE conditions, WHERE column, WHERE operators, WHERE value) and trained each classification model.
However, pre-trained language model (BERT, etc.) was used to cope with the variability of natural language (same words but different expressions), attention was used to map natural language to database schema, and a technique called execution-guided decoding was used to improve performance. Introduced. As a result, the results were quite good for WikiSQL, but not all of the problems were solved. This is because WikiSQL itself is a very limited form of data for practical use.
For example, WikiSQL doesn't really have a frequently used JOIN operation. Also, there is no semantic value that can only be known by knowing the current date, such as “last month”. In addition, schemas of similar names, namely,'estimated annual salary','current salary','creation date' and'modified date','final salary' and'annual salary', etc. It's clean data, but the databases actually used are often full of ambiguous schemas.^^ The author tried several things to solve these problems, but in the end, instead of designing a more complex model for these mutations, it was learned. We chose the direction of applying a number of techniques to augmentation data in various ways.
It's not enough to actually replace humans yet, but I think it's a study that shows enough potential. However, the current classification-based technology is exceeding the performance of the generation-based technology, and this is entirely tailored to the language of SQL, so I wonder if this trend will continue in the future.