
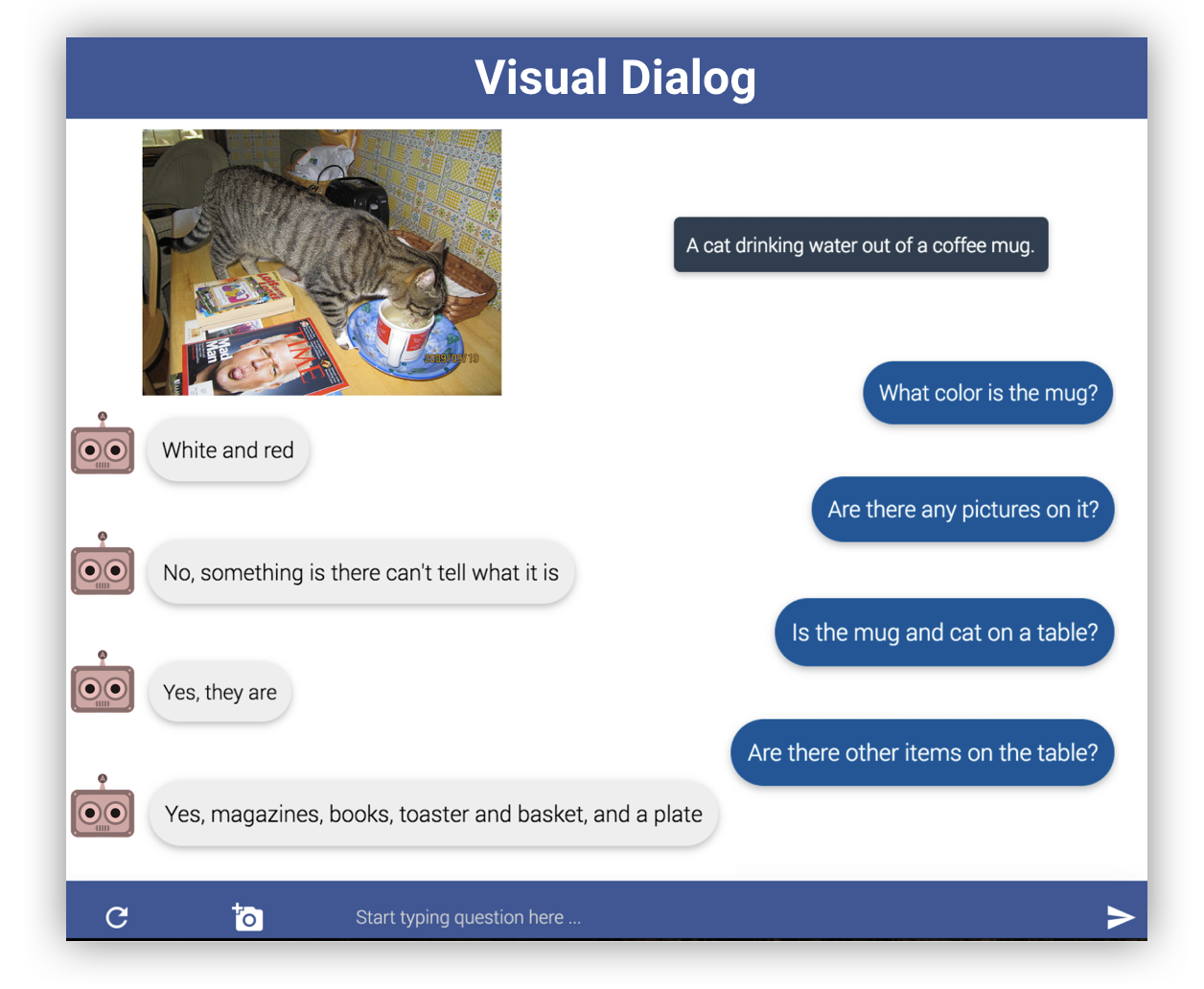
The Visual Dialog task is a multimodal task that adds an image to a Q&A task that consists of a question and answer. For example, if you give a picture of a white cat and a black dog together and ask, "What color is the animal next to the cat?", you answer "black". Specifically, it is a task that generates an answer by giving an image, dialog history, and question. If you go to the Visual Dialog site, the dataset is public and there are 120,000 images and 1.2 million text sentences based on v1.0. (1 conversation per image) The link below is the dataset page of the Visual Dialog site.
This site holds a challenge every year, and the video below is an introduction to the technology of the team that ranked first with a system called MReaL-BDAI. Based on the NDCG, one of the evaluation metrics, it achieved a remarkable score of nearly 10 points above second place. (74.57)
However, if you read the papers of this technology, it is not a new model structure, but rather, it is raised to 74 points with various (task dependent) intuitive optimization techniques on the existing NDCG's 59-point technology. (I raise the NDCG by 10 points only by the method introduced as the 2-step learning method) And through a follow-up paper, the methods optimized for the currently defined Visual Dialog Task will be described in detail. I haven't read the paper yet, but I think there is a tendency to optimize it for a specific task or specific metric. (For example, in the case of MRR, it is 10 points or more behind the 3rd place team) The link to paper are also attached.
MReaL-BDAI, for Visual Dialog Challenge 2019: two causal principles for
improving Visual Dialog (VisDial). By “improving”, we mean that they can
promote almost every existing VisDial model to the state-of-the-art performance
on t…
Although Visual Dialog Task has some problems and evaluation metrics are also different from actual performance, I think multimodal conversation is an important field that can become one of the future chatbot directions. When talking with each other, we do not rely solely on verbal information, but also rely on a variety of information such as visual, auditory, and olfactory information. I think chatbots can read our expressions and talk to us, and if we 'see' and 'listen' to hear the same things we see, the breadth of the conversation will be much wider. We look forward to a chatbot talking with us while watching and listening to BTS performances together.






