The convolution commonly used in images is a 3D operation. (KxKxC; K=kernel size, C=number of channels) After applying this by dividing it into multiple 2D operations of KxKx1, depthwise separable convolution that applies a convolution with a size of 1x1xC in the channel direction greatly reduces the number of parameters. The network structure created in this way is Google MobileNet.
Google Inception has a basic module of concatenation after applying kernels of different sizes such as 3×3, 5×5, and 7×7 to the input tensor. The advantage of this method is also the reduction in the number of parameters based on the same performance.
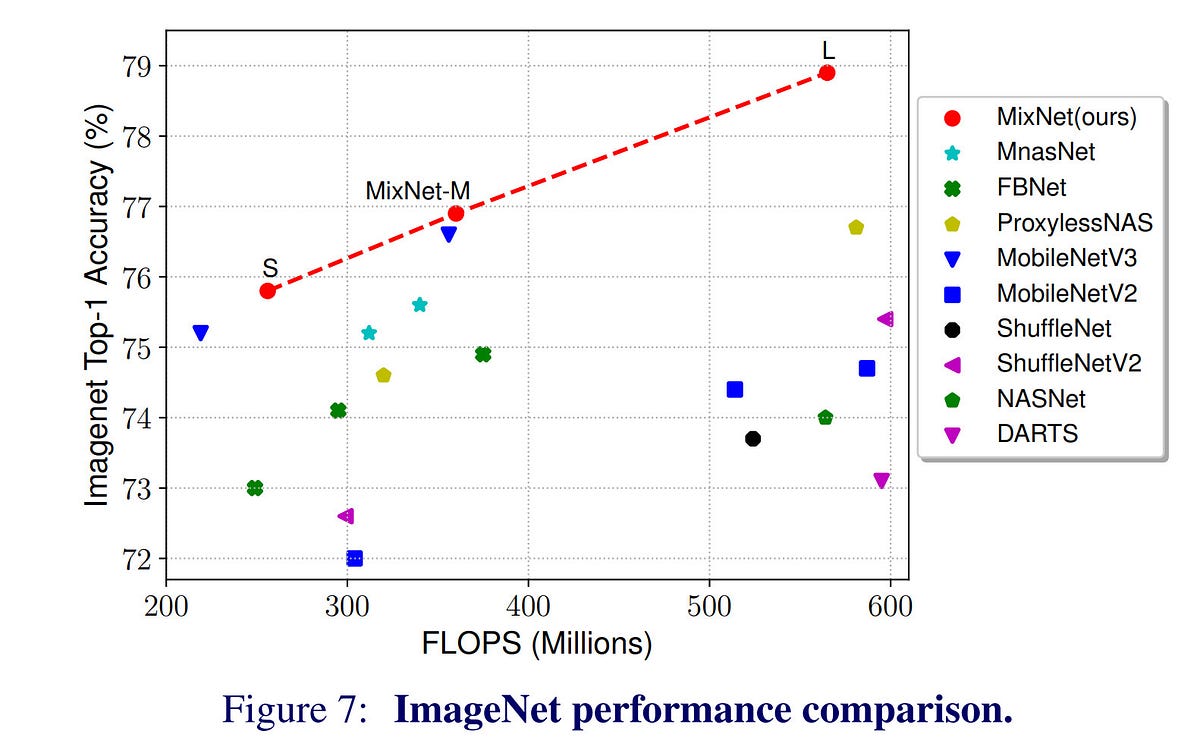
Google MixNet shared in the link below has a structure that combines the above two characteristics into one. In other words, while using depthwise separable convolution, kernels of various sizes are applied. The results of the experiment are amazing. In ImageNet-1K task, compared to ResNet-153, it shows the same performance with only 1/12 of parameters and 1/28 of operations.
However, that does not mean that MixNet is 28 times faster than ResNet. In general, for the most efficient GPU operation, the “large” “same” operation must be repeated, but the depthwise convolution is more complex than the standard convolution because it is split and applied each convolution, and eventually there is no difference in performance as much as the number of operations decreases. The same goes for Inception. It is more complicated because it divides into multiple kernels and performs each operation, and is slower than the non-inception structure. Also, because “branching” occurs, the required memory also increases in simple implementation.
For reference, in the case of a residual network, that is, skip connection, the number of parameters is not increased by 1 degree, and the amount of calculation calculated by simply MFLOPS is almost the same, but when measured in practice, the execution time is significantly affected. (I understand that it is also because “branching” occurs.) The memory required to store each before and after filtering increases as well.
This does not mean that MixNet is bad, and I will use it later ^^, but I think that the complexity of the network cannot be fully expressed only with the number of parameters and operations. In fact, MixNet-S has 30% fewer parameters than MobileNet-V3, but MobileNet-V3 came out twice as fast in the inference test conducted by Google Pixel ^^;; I think “structural simplicity” and “implementation feasibility” are actually very important. For reference, it's even more pronounced when it comes to hardware implementation. There is a difference in implementation cost between 3×3, 5×5, and 7×7, which is much more than the difference in the number of parameters.