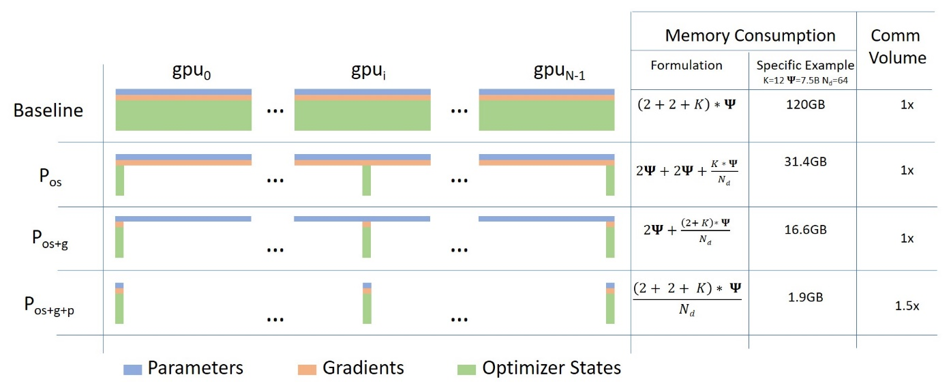
As the number of parameters of a deep learning model increases significantly, the memory required for training is also increasing. OpenAI's GPT-2 consists of 1.5B parameters, and Google's mT5 also has a number of parameters up to 13B. In addition, the number of parameters of OpenAI's GPT-3 reaches 175B. In the case of such large models, even if you try fine-tuning with small data, it is difficult to try it easily because it requires a large amount of GPU memory.
A paper published by Microsoft, “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models” covers techniques to mitigate this problem and is known to significantly reduce the amount of maximum memory required. Here is a link to the paper:
billions to trillions of parameters is challenging. Existing solutions such as
data and model parallelisms exhibit fundamental limitations to fit these models
into limited device memory, while obtaining computation, communicat…
Microsoft has published a number of technologies implemented in this paper under the name DeepSpeed. Using DeepSpeed, it is said that memory requirements can be reduced by 1/10 compared to the previous one, allowing the use of 10 times larger batch size or 10 times larger model. Microsoft used this library to train a model with 17B parameters called Turing-NLG. Meanwhile, Facebook also released the technology implemented in the paper under the name FairScale. Here are links to DeepSpeed and FairScale's github repositories:


In addition, HuggingFace, which is well known as a natural language framework, implemented DeepSpeed and FairScale in version 4.2.0, and made it easy to use by setting a few parameters. For example, in the case of the mT5-3B model with 3B parameters, one RTX 3090 24G GPU will cause a memory error even with a batch size of 1, but it is said that if you use DeepSpeed, FairScale, and FP16 at the same time, you can learn with a batch size of 20. We share articles with relevant analysis: