
Since the advent of AlexNet consisting of multiple convolution layers, there have been many studies on the structure of deep learning models.
For example, Google Inception used a method of increasing efficiency per parameter by creating and concatenation of convolution layers with different kernel sizes such as 3×3, 5×5, 7×7, etc., and Microsoft ResNet used skip connection, In other words, by creating one more data path that does not go through the convolution layer and adding it to the result of passing through the convolution layer, gradient vanishing is prevented even in a complex structure with thousands or more layers. Both of these methods are simple and efficient, so they are actively used to design other deep learning models.
On the other hand, although the approach is different, a technique called depthwise separable convolution was used in Google MobileNet and Xception in order to reduce the complexity while increasing the performance per parameter, and in ShuffleNet, the complexity was reduced by adding a randomly shuffling layer.
However, in the case of inception, the combination of 3×3, 5×5, and 7×7 kernels is mathematically a subset of the use of only 7×7 kernels, so it is meaningful in reducing complexity rather than improving model expression. In fact, compared to using one kernel, there are many data paths, so the speed improvement is not significant compared to reducing the number of parameters. This is the same with depthwise separable convolution. In the case of depthwise convolution, which is a form of group convolution, it can be seen as a combination of 2D convolution and 1D convolution. In this case, the number of parameters decreases drastically compared to using 3D convolution, but performance after actual implementation The improvement is not very large. This can be seen as a decrease in efficiency from decomposing one parallel operation into two operations.
In the case of ResNet, there have been many sub-studies on why learning works well. Analysis that the modeling of the residual signal with relatively reduced variation can be more effective because adding the signal that has passed through the convolution layer and the signal that is not is similar to decomposing the original signal into a predicted value and a residual signal (increasing modeling power). On the other hand, there were opinions that it was simply a form of ensemble (learning technique) after learning by dividing multiple layers into smaller layers. To further explain, in the latter case, the use of skip connection can actually play a role of skipping one convolution layer, resulting in an effect of reducing the number of layers.
Personally, my experience of continuously observing the change of weight while training a deep learning model of the ResNet series was similar. In other words, skip connection is used more in the early stage of learning, but as the learning progresses gradually, the role of skip connection decreases. In addition, in the learning stage, ResNet is used, but after the learning is completed, I have seen a case where skip connection is removed and a few epochs are further trained to achieve similar performance.
The authors of RepVGG tried to increase the performance with only the convolution layer without using multiple data paths and complex structures such as Inception or Residual Network. What's interesting about this attempt is to use the model structure differently in the learning and inference stages. The following is the picture included in the paper:
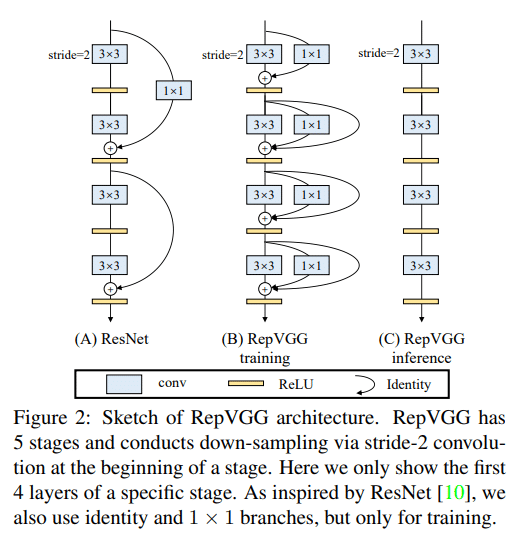
In general, ResNet repeats the Input-Relu-Conv-Output combination, which uses a method of aligning the dimensions with 1×1 convolution and then adding it to the output. There is a nonlinear function, Relu, between Input and Output. In contrast, RepVGG divides Conv itself, which is a linear operation step, into multiple data paths. Each divided path is composed of convolutions with various kernels such as 3×3 convolution and 1×1 convolution. It is said that learning was performed well without gradient vanishing problem, and was able to have better performance compared to existing models such as ResNet.
Note that since only the linear operation step is divided into several data paths, these data paths can be combined into one convolution by simple calculation after training is complete. The authors of RepVGG named this structural re-parameterization, and after this process, it eventually converges with one simple convolution operation, which can be used in the inference stage. In RepVGG, as a result, only 3×3 convolution was used, and because skip connection was not used, it was expressed as VGG-like. The result of this implementation has a simple data path and is advantageous for hardware implementation. As a result of the actual experiment, even when it is run by software, it is much faster and has better performance than ResNet.
The above results suggest that Residual Network is not a technology for improving model expression, but a technology for improving ease of learning. Of course, that doesn't mean that Residual Network is not a useful technology, but the experimental results of RepVGG are more interesting in that we could understand the role of skip connection more clearly. RepVGG share on github.







