
Google Lyra is a new speech compression method based on the generation model, and it is possible to obtain transparent quality with only a low bandwidth of 3 kbps by greatly improving the sound quality of the original voice, that is, about 8-16 kbps required to obtain transparent quality. It is characterized by being there. Here are some related blog posts:
Voice compression has distinct characteristics from audio compression, image compression, and video compression. For example, audio compression has evolved into a method of modeling the characteristics of the human ear, not a sound source generation model, but an auditory model, since it has to deal with a form in which a number of sound sources are combined. Image compression partially reflects the visual characteristics that low-frequency components are more visually sensitive than high-frequency components, but does not actively utilize cognitive characteristics like speech compression or audio compression. Video compression is basically based on image compression technology, and motion tracking technology that utilizes high similarity of adjacent images in time series is added.
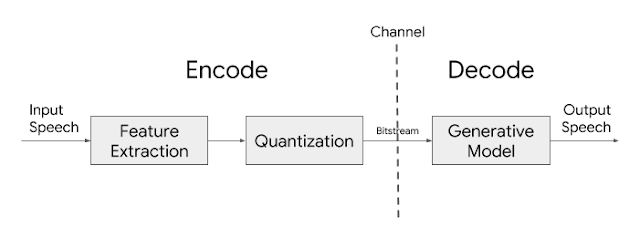
On the other hand, since the mechanism of voice generation has been clearly identified, compression technology has been developed as a method of modeling human vocal organs. Specifically, a voiced or unvoiced signal is created depending on whether the exhalation caused by the contraction of the lungs passes through the vocal cords, and a specific frequency range is emphasized according to the shape of the mouth and the position of the tongue. To this end, low-band speech compression algorithms extract the vocal fold vibration frequency (F0), voiced or unvoiced sound (voiced/unvoiced), and frequency-enhanced form (spectral envelope) as parameters, quantize them, transmit them, and then synthesize them. This method is called parametric speech coding, and Google Lyra basically has the same structure.
Among various speech compression technologies, MBE (multi-band excitation), published by Griffin in 1987, also has a parametric speech coding structure. MBE divides the frequency domain into equally sized bands, transmits the energy of these bands, and determines voiced/unvoiced information for each band. If it is a characteristic part, the MBE decoder, that is, the part that restores the speech signal, uses the Griffin-Lim algorithm, which is the same algorithm that is widely used in deep learning-based TTS. Any signal can be expressed as the sum of multiple sine waves, and each sine wave has its own energy and phase information. The Griffin-Lim algorithm is a method to restore a signal when only energy is given and there is no phase information. Compared to the WaveNet series of algorithms, the Griffin-Lim algorithm has a fundamental limitation in terms of sound quality.
Although technical details about Google Lyra have not been disclosed, it is known to follow a method similar to mixed-excitation linear prediction (MELP). MELP is similar to MBE, but it is more efficient by calculating and transmitting linear prediction coefficients than MBE, which expresses the spectral envelope as energies for each band. In addition, voiced/unvoiced sound information is not transmitted for each band, but only the cut-off frequency is transmitted using the fact that voiced sounds exist in the low-frequency region and unvoiced sounds are in the high-frequency region. Will be expressed.
Predicting from this, it is assumed that Google Lyra has a structure similar to MELP, but uses WaveRNN instead of Griffin-Lim algorithm as a synthesizer. In the case of deep learning-based TTS, even if the encoder part is the same, it seems that the sound quality was significantly improved by replacing the MELP synthesizer with WaveRNN instead of Griffin-Lim, considering that the sound quality differs greatly depending on the type of synthesizer algorithm.
Compared to Griffin-Lim, WaveRNN is still very complex, and the bandwidth required for voice signal transmission is significantly lower than for images and videos, so it is true that the need to increase the compression rate is relatively low. For example, if 16 kbps is lowered to 3 kbps, the bandwidth is reduced to 1/5, but considering that the bandwidth required to transmit Full-HD video is several Mbps or more, the total reduction is only 1%. So, it doesn't seem like a big need to apply technologies like Google Lyra to video services like YouTube. Instead, it would be very useful for audio-based services that have been rapidly increasing in use in recent years, such as Clubhouse, and in this case, the main technical challenge will be to reduce the complexity, that is, operation on the device as much as possible. Existing voice compression technologies have already been implemented in an effective way in smartphones, and the battery consumption will be significantly lower.






