Transformers made to be applied to the field of natural language processing have recently been applied not only to text but also to various data such as images and videos, showing excellent performance. However, text, image, and video have only the difference of 1D, 2D, and 3D data, respectively, and can be viewed as unstructured data that is essentially arranged in a row. Therefore, the same transformer algorithm can be applied without major changes.
Data in the real world do not exist independently but often have a structured form by the relationship between the data. Netflix and YouTube videos, users' preferences, gamers and their games or purchased items, and even human knowledge itself is not a simple listing, but rather a structured data that is intricately intertwined with each other. Recently, graph databases are in the spotlight as a means to express these data. Each data is represented as an entity in the graph database, each entity is connected by a relationship, and each relationship has a property.
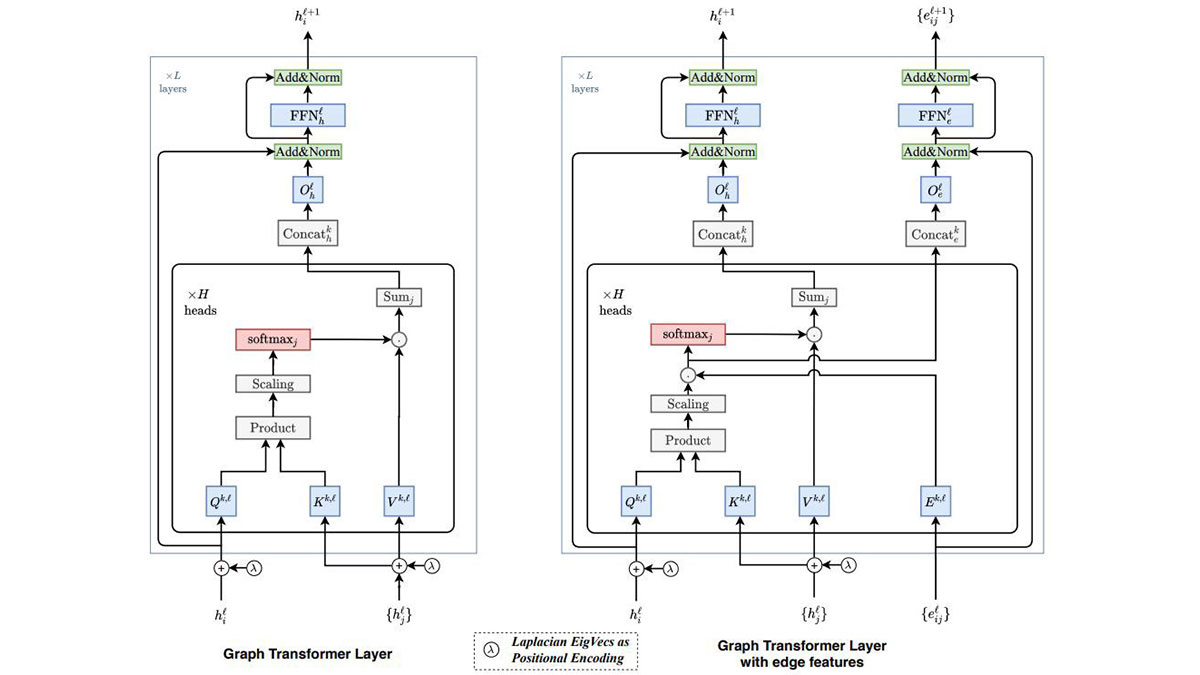
Graph transformer is a transformation of an existing transformer so that structured data represented as a graph can be used as input. In other words, it aims to learn not only the characteristics of each data but also the relationship between the data. To this end, two major changes have been made.
The first is attention. In the case of natural language data, attention is usually implemented through connections with all other words in a sentence. Of course, attention could be implemented by connecting all the nodes in the graph, but it is not efficient because the number of nodes in the graph database can be huge compared to the number of words in a sentence, which is only a few tens of words at most. Graph transformers alleviate this problem by limiting attention to connections with adjacent nodes. Depending on the field of application, it seems that not only adjacent nodes (primary neighbors) but also adjacent nodes and re-adjacent nodes (secondary neighbors) can be expanded.
The second is positional encoding. Positional encoding is used to preserve the unique positional information of each entity in the given data. For example, each word in a sentence has a different positional encoding vector, and by reflecting this, it is possible to learn to have different meanings when the order of appearance of words in a sentence is changed. However, unlike sentences in natural language, which is a one-dimensional array, the nodes of the graph are connected in a much more complex manner, so a more general method should be used. In a graph transformer, the Laplacian matrix, which is an extension of the adjacent matrix that represents the connection type of each node in the graph, is decomposed into a number of eigenvectors, and all nodes select some of these eigenvectors and use them as a positional encoding vector. When this Laplacian positional encoding is applied to a linearly connected graph, it becomes the same as the sinusoidal positional encoding used in the existing transformer, so the authors say that this method is an extension of the existing method.
If the AI technologies that have been researched have been mainly targeting media data such as text, images, video, and voice, then I expect that more and more AI technologies targeting structured data will appear in the future. Share articles related to Graph transformer.