
[Prior Research Team Sung-Hyun Kim]
Modern language models are trained using a large-scale corpus. In particular, for models using decoder neural networks such as GPT-2, BART, and T5 models, natural language can be generated by repeatedly sampling the next token. Here, you can control attributes such as themes, styles, and sentiments of the natural language generated by the method of sampling. In this post, I would like to introduce an effective decoding sampling strategy that can be used when generating natural language. Well-known decoding strategies are greedy search and beam search.
- Greedy search
In the case of a Greedy search, it simply selects the word with the highest probability as the next word.
In terms of formula, it is 𝑤𝑡=𝑎𝑟𝑔𝑚𝑎𝑥𝑤𝑃(𝑤|𝑤1:𝑡−1), where t stands for each timestep.
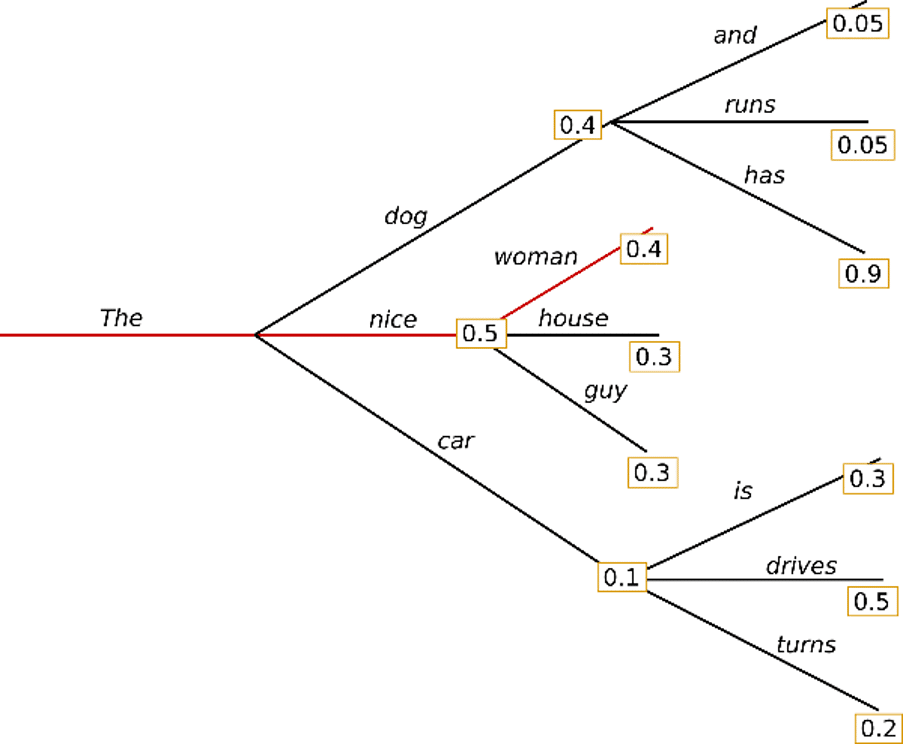
The Greedy search algorithm can start with the word'The' and select the word with the highest probability of “nice” as the next word. Finally, the sentence “The nice woman” is generated, and the total probability is calculated as 0.5 * 0.4 = 0.2. However, in this case, certain phrases will be generated over and over again.
- Beam search
Beam search searches the probability as much as the beam width, which is a specific number per tree level, and selects the tree with the highest probability.
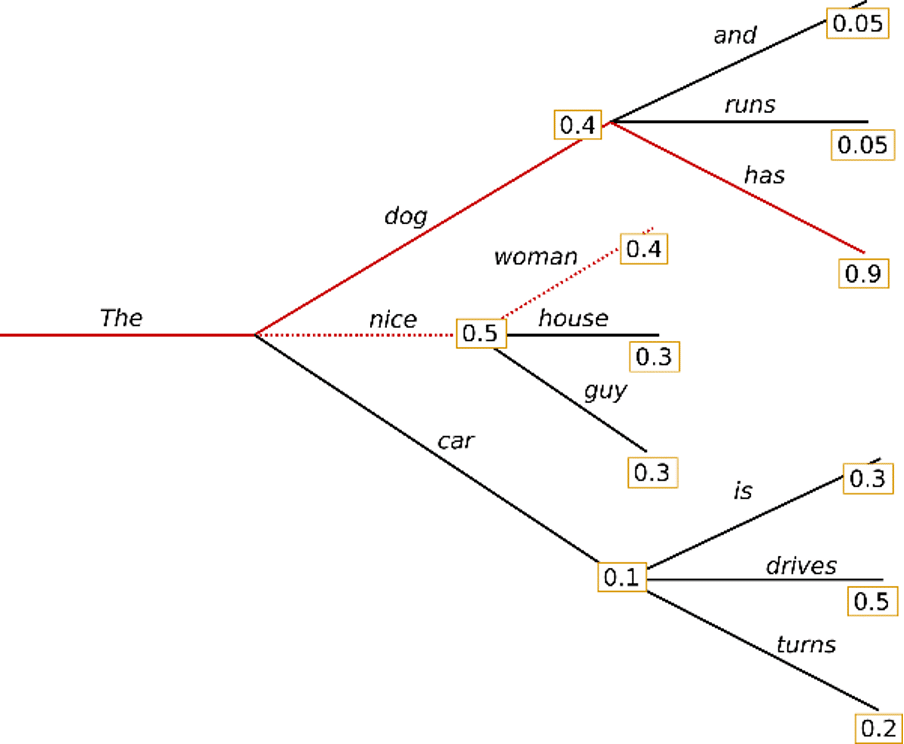
For example, this is an example when the beam width is set to '2'. At this point, out of “dog”, “nice”, and “car” that can appear after “The”, we start to search together two hypotheses, “dog” and “nice”, which have the highest probability of coming out.
As a result, it was found that the probability of “The dog has” was higher at 0.36 than the probability of “The nice woman” which was selected by greedy search 0.2 In the case of such a beam search, it may have the following characteristics.
- It can work well for tasks where the desired length of sentence generation is predictable, such as machine translation or sentence summarization. However, it doesn't work smoothly in open-ended creations, where the output length can vary significantly, such as dialogue or story creation. (Murray et al. (2018), Yang et al. (2018))
- Beam search is vulnerable to the iterative generation problem.
Also, Ari Holtzman et al. According to the (2019) paper, human-chosen language will have a higher variance.
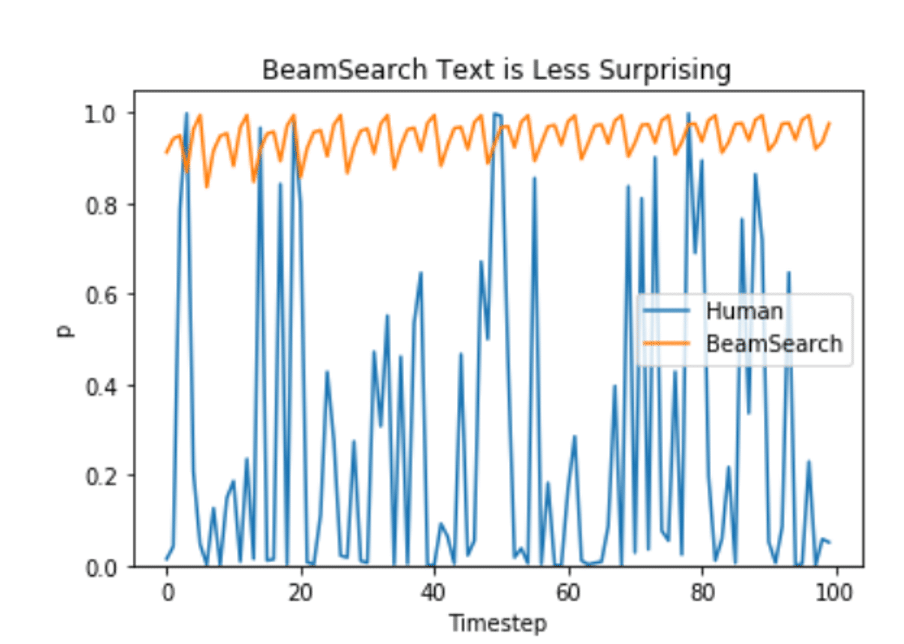
So what's a better generation strategy?
Let's take a look at the KoGPT-2 based natural language generation strategy through the practice code below.
https://colab.research.google.com/drive/1yUGVmQ0nj8Hd3h0YV6PemQx0FtzpefGB?usp=sharing
references
https://lilianweng.github.io/lil-log/2021/01/02/controllable-neural-text-generation.html
https://huggingface.co/blog/how-to-generate






