
[Service Development Team, Kyunghwan Lee]
We usually come across a bunch of unlabeled data while training a model, and we often run into the problem of Data Annotation. This is because it would be too time-consuming and expensive to label all unlabeled data one by one. For this reason, there are many cases where annotation is performed by randomly selecting data. If you select and label data at random, it is likely that the proportion of data that the network has difficulty predicting an answer will be small, which will help improve the performance of your model. If data-driven learning that makes it easy for the network to predict the answer is already carried out, when data that is difficult for the actual network to predict comes out, the answer will be difficult to match.
Active Learning is a technology that helps users to learn data efficiently by identifying data that the model has difficulty with. How the model determines which data is difficult is the core of Active Learning. As it is a technology that has been developed for more than 20 years, various identification methods exist. Examples are Uncertainty-Based Approach, Diversity-Based Approach, and Expected Model Change. However, the above three approaches have limitations, such as being difficult to use universally or difficult to apply to deep learning networks due to the large amount of computation.
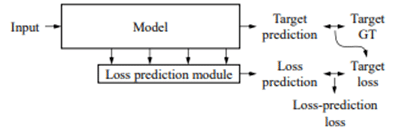
Learning Loss for Active Learning (CVPR 19) proposes a general-purpose Loss prediction module that is easy to apply to deep learning networks.

Another network, Loss prediction module, is placed next to the main model (also called target module, ex. image classification model) to predict the loss. It is a method of estimating the loss of the input data to determine the data that the network finds difficult to learn.
As the loss function, Margin Ranking Loss was used. You may wonder why the relatively popular Mean Squared Loss (MSE) method was not used, but when using MSE, there is a limitation in that the scale of the target loss continues to change. Therefore, we used Margin Ranking Loss, which is not affected by the scale change of the target loss.

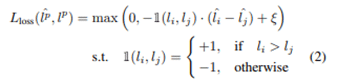
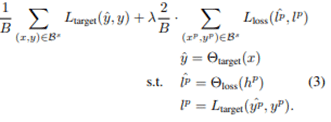
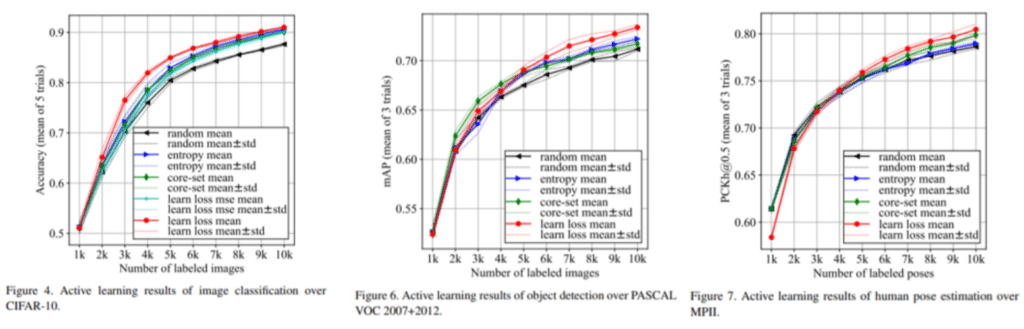
In this paper, we conducted experiments on three tasks, such as Image Classification, Object Detection, and Pose Estimation, and share the fact that relatively good results were obtained compared to other active learning methods. The CIFAR 10 dataset / PASCAL VOC 2007 + 2012 dataset / MPI dataset were used, respectively, and the performance was proved superior in comparison with the Random Sampling method, Entropy-based Sampling, and Core-set Sampling method. In all three tasks, performances that surpassed existing methodologies were demonstrated.
As AI technology advances more and more, it becomes increasingly necessary to label large amounts of data. We conclude this article by suggesting that you use the Loss prediction module solution presented in Learning Loss for Active Learning.
Reference – Paper: https://arxiv.org/abs/1905.03677
Reference – https://kmhana.tistory.com/10






