
[Service Development Team Hwang Jun-sun]
When supervised learning a machine learning model, if a dataset with an unbalanced number of data between labels is used as the training data, it will suffer from a phenomenon in which the learning of samples belonging to a label with a small ratio is not performed well. If there is simply a small number of samples, the training will not be performed well, and even if there are enough samples to learn, the model will have bias if the ratio difference is extreme. This is especially common, for example, when the problem of classifying anomalous data is a problem with too many labels to classify. In this case, no matter how good the state-of-the-art model is, it is difficult to derive the correct performance. There are four main ways to solve these problems.
- Use of appropriate evaluation metrics
Rather than being part of a method to directly solve the imbalanced dataset problem, it can be said that it is the first step to accurately interpret and understand the currently trained model and apply the solution that will be described later. For example, suppose we have a problem of binary classification of labels 0 and 1, and the proportion of samples belonging to label 0 to the entire dataset is 99% and the proportion of samples belonging to label 1 is 1%. If the trained model classifies all data as 0, the accuracy of this model will be 99%. Although this accuracy is not an incorrect indicator, can this 99% performance indicator properly tell the performance of this model? In general, we want to classify 1s correctly, not 0s in these data. If so, this indicator would not be worthwhile. Therefore, it is recommended to use the following evaluation index [1], which can see not only accuracy but also various aspects.
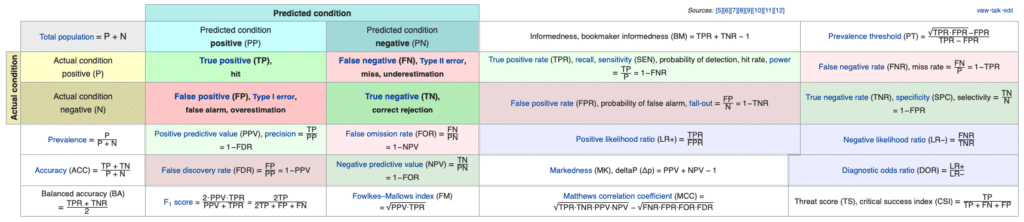
- Precision: True Positive / (True Positive + False Positive); The percentage of what the model classifies as true that are actually true (fit)
- Recall: True Positive / (True Positive + False Negative); Proportion of (fit) the model predicted to be true out of what is actually true
- F1 score: 2 * Precision * Recall / (Precision + Recall); Harmonic mean of precision and recall
- ACU: refers to the area under the ROC curve, a graph showing the performance of a classification model at all thresholds
Among the above indicators, it can be seen that the precision and recall for the label with a small ratio are very low. In other words, it has not been well-trained for that label.
- Sampling the training dataset
If it is determined that the model has not been trained well through the above evaluation indicators, this is the first strategy that can be applied simply. You can solve the imbalance problem by matching the ratio between labels.
- Under-sampling [2]: Creating a balanced dataset by reducing the number of samples that occupy a large proportion, a method that can be used when the amount of data is sufficient.
- Over-sampling [3]: Creating a balanced dataset by increasing the number of samples occupying a small proportion, a method that can be used when the amount of data is insufficient. (ex. repetition, bootstrapping, SMOTE, ROSE)
A proper combination of the above two methods [4] will lead to a better sampler. In addition, the Imbalanced Dataset Sampler[5] applicable to PyTorch, which is commonly used as a deep learning framework, has been released, so it would be good to refer to it. However, if the data belonging to the label you want to classify is extremely small and not enough to learn, the sampling method alone may not be able to solve it.
- Data Augmentation
This method can be used when the number of data is extremely small. However, whether and how to apply this data augmentation method will differ depending on the task depending on the domain.
- Image Augmentation

- Text Augmentation
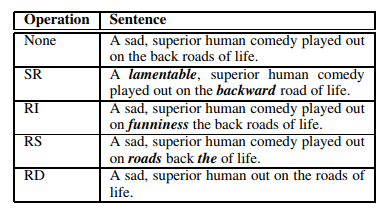
The above example is a data augmentation technique that is universally applied to image and text data. If you use the samples with a label with a low ratio rather than a label with a high ratio already, you can increase the performance by augmenting them.
- Using loss functions for unbalanced datasets
Finally, to use a loss function that fits unbalanced data. One of the most popular loss functions for unbalanced data is Focal Loss[6]. In addition to this, various loss functions exist, and there is also LADE Loss[7], which will be introduced in CVPR 2021.
- Focal Loss: Solved by weighting the loss value based on the classification error
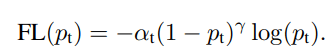
LADE Loss: Solved by distributing the label distribution of the unbalanced training data to the label distribution of the target data.
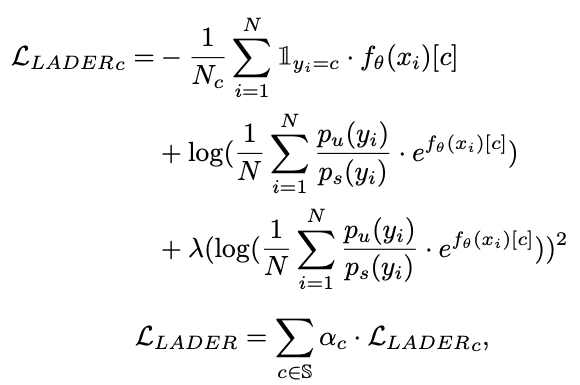
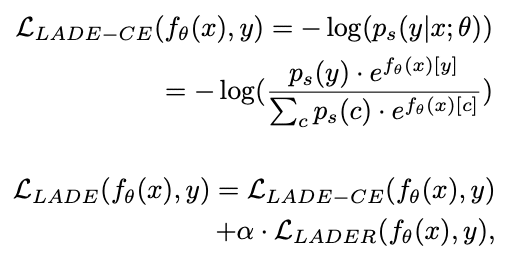
A more fundamental solution than the described method is to acquire more datasets. However, the cost of collecting the appropriate dataset and labeling is significant. If the amount of data set used for the problem you are trying to solve is not sufficient enough to train the machine learning model, all of the above methods may not solve it. If the dataset is sufficient, but highly imbalanced, the above method may be applied to drive performance. The last method, the method using the loss function, will be shared as code and I will finish the post.
https://github.com/Joonsun-Hwang/imbalance-loss-test/blob/main/Loss%20Test.ipynb
[1] https://en.wikipedia.org/wiki/Precision_and_recall
[2] https://imbalanced-learn.org/stable/under_sampling.html
[3] https://imbalanced-learn.org/stable/over_sampling.html
[4] https://imbalanced-learn.org/stable/combine.html
[5] https://github.com/ufoym/imbalanced-dataset-sampler
[6] https://arxiv.org/abs/1708.02002
[7] https://github.com/hyperconnect/LADE






