[Prior Research Team Yoo Hee-Jo]
Text-to-speech (TTS) is a technology that converts arbitrary text into a voice of a specific voice and calculates it. After Google announced the Tacotron series, it quickly switched from HMM (hidden Markov model)-based to deep-learning-based, and currently commercial serviced models often operate on the basis of deep-learning. Improvements are being made enough to be commercialized, and related research is also moving away from 'simple implementation' and gradually considering 'new functions' and 'optimization'.
Neo Sapiens recently unveiled the MLP Singer, a new TTS model that sings just as its name suggests. While Microsoft's HiFiSinger, which was released as the existing Non autoregressive Singing TTS, used a duration predictor for the Transformer, it is a significantly improved model in terms of weight reduction by excluding the duration predictor and using the MLP mixer instead of the Transformer.
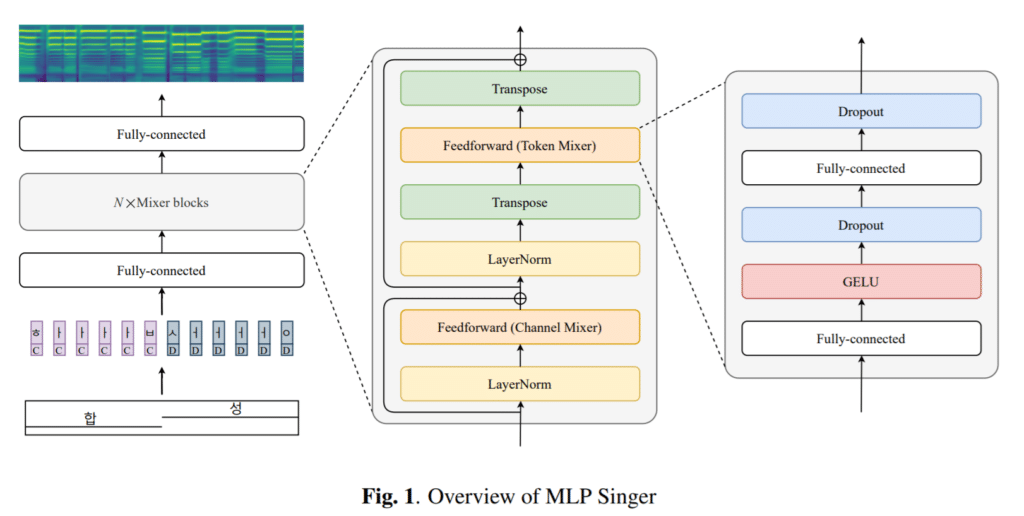
Of course, while the recently commercialized TTS MOS exceeds the 4 point range and produces a voice that is almost indistinguishable from humans, the TTS of the released model is still in the early 3 point range, so there seems to be a lot of room for improvement. However, like the existing TTSs, it is expected to develop rapidly through data accumulation and model refinement.
The Korean/English song data set released by KAIST last year was also released in May, and demos learned from the data are publicly available, so you might want to listen to it. For more details, please refer to the link below, which is a demo site published in the paper.
Demo link: https://mlpsinger.github.io/
Github link: https://github.com/neosapience/mlp-singer
Reference
Tae, J., Kim, H., & Lee, Y. (2021). MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis. arXiv preprint arXiv:2106.07886.
Choi, S., Kim, W., Park, S., Yong, S., & Nam, J. (2020, October). Children's Song Dataset for Singing Voice Research. In The 21th International Society for Music Information Retrieval Conference (ISMIR). International Society for Music Information Retrieval.
Chen, J., Tan, X., Luan, J., Qin, T., & Liu, T.Y. (2020). Hifisinger: Towards high-fidelity neural singing voice synthesis. arXiv preprint arXiv:2009.01776.






