
[Prior Research Team Hongmae Shim]
As super-giant language models such as Open AI's GPT-3 and NAVER's Hyper CLOVA are unveiled, various examples and services using them are pouring out recently. All of these super-giant language models have an amazing ability to learn how to perform a new task on their own just by presenting simple examples related to a new task (= task) without gradient updates. However, while these language models perform text-based tasks well, they do not fully demonstrate their abilities for tasks other than text such as Visual Task.
Recently, DeepMind disclosed a method called Frozen that can perform Visual Tasks for autoregressive language models through a paper. In this paper, we proposed a simple and effective method to transfer few-shot learning capabilities to “multi-modal”. By learning the vision encoder to represent each image as a sequence of continuous embeddings using image-caption pair data, pre-trained, frozen language models can generate appropriate captions using this prefix information.
Figure [1] shows the overall system structure including the vision encoder introduced in this paper. In the figure, the parameters of the two Language Models are fixed and frozen. Vision Encoder uses the image encoding information on the left and some encoding information on the right caption to learn the Language Model (Self Attention Layers) to generate the rest of the caption. The weights of the language model remain fixed, but the gradient is propagated back through it to train the image encoder from scratch.
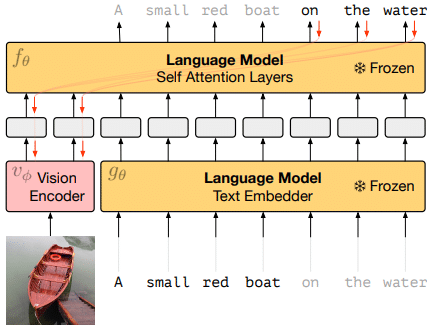
Frozen that has been trained using the above structure is called a multimodal few-shot learner in this paper. Frozen is trained on a single image-caption pair, but once trained it can also effectively respond to sets aligned with multiple images and text. Moreover, it has an amazing ability to learn new tasks even in untrained multi-modal tasks such as Visual Question Answering (VQA) by leveraging pre-trained language models. In this paper, in order to improve the few-shot learning performance of frozen in a multi-modal task, an experiment was conducted while comparing shots for multiple tasks.
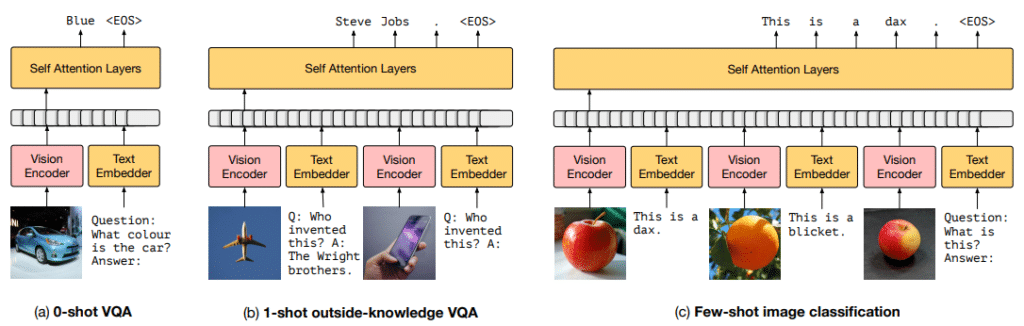
Figure [3] below shows the test results of the test data after applying the optimal settings obtained through the above experiment to the Frozen model. If you look at the first line of the figure, if you put two images and a caption as examples, and at the end provide an image and text information “Who is this person” as a suggestive word, the model creates a final “horror” emoji. The second line also gives an example of a similar format. Here, only information about “airplane” can be obtained as image information, but factual knowledge is also included in the language model, so the final model is the “Wright brothers” for the person who invented the airplane. We can create an answer for you. The attractive point of Frozen is that it can perform such tasks by combining vision information and factual knowledge information of language models.

The goal of developing Frozen was not to maximize performance in a specific task, so it has the necessary abilities to perform the task, but there is still a difference from SOTA's performance for a specific task that is learned in a few-shot. However, the performance in various tasks far exceeds the baseline without looking at all the necessary training examples provided by the benchmark. Also, as shown in Figure [3], Frozen often produces attractive outputs, which can be viewed as a system for making truly open and unconstrained linguistic interpretations of images.
So far, we have introduced how to convert a large-scale language model into a multimodal few-shot learning system using Frozen. For more details, please refer to the thesis.
Reference
[1] Tsimpoukelli, M., Menick, J., Cabi, S., Eslami, S.M., Vinyals, O., & Hill, F. (2021). Multimodal Few-Shot Learning with Frozen Language Models. arXiv preprint arXiv:2106.13884.
[2] https://www.youtube.com/watch?v=FYA_jwPpXi0






