
[Prior Research Team Yoo Hee-Jo]
Translation has been a research topic since the early days of the deep learning boom. Attention, which is now used in any field, was also the first proposed method to solve the problem of the Seq2Seq structure. The performance of deep learning-based translators has been steadily improving for the past 10 years, and this improvement in translator performance has resolved many of the language barriers.
Current translation technologies are mostly focused on text-to-text (text-to-text translation, T2TT). And while the abstraction of the text is great for taking the model to a certain level, it has the problem of dissipating various non-verbal elements within the conversation. This problem is especially noticeable in conversations. When two people with different languages use a translator, we usually go through a process like 'L1 speech → L1 recognition (L1 text) → L1L2 translation (L2 text) → L2 TTS (L2 speech)'. Non-verbal information that disappears through recognition and translation becomes a barrier that is difficult to overcome with the current translator.
As a solution to this problem, Google released Translatotron in 2019 and Translatotron 2 this July. The main difference between Translatotron and conventional translation models is that it focuses on speech-to-speech (speech-to-speech translation, S2ST). The paper that published the model says that S2ST has advantages such as the fact that it can reflect the non-verbal information of L1 in speech output as it is compared to T2TT, and the time and error reduction due to the reduction of the calculation process, etc.
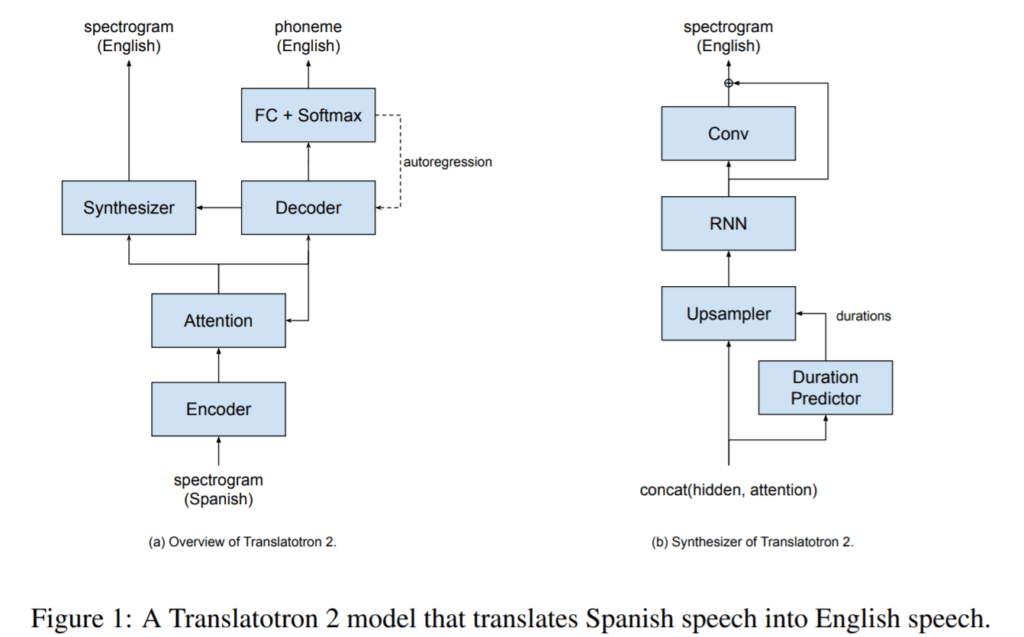
The rough structure of Translatotron 2 is close to that of a mixed ASR and TTS model. It receives L1 voice information (mel-spectrogram) and predicts L2 phoneme with a decoder (ASR), and at the same time predicts L2 mel-spectrogram through a synthesizer by combining the decoder output and attention before calculating L2 phoneme (TTS) . Therefore, the L1 phoneme is not considered in the model.
Of course, this structure shows that the S2ST technology still has many obstacles to overcome. The proposed model is closer to the structure of speech-to-text-to-speech rather than the targeted speech-to-speech by going through a decoder for text output. There is a high possibility that the quality of the model will also vary depending on the degree of difference between L1 and L2. In particular, the attention used for the decoder will show much lower performance in a language with a different word order, such as Korean. But nevertheless, these models are asking, 'Isn't deep learning going to allow us to one day overcome the many language barriers we face?' It also raises expectations.
Reference
Jia, Y., Ramanovich, M.T., Remez, T., & Pomerantz, R. (2021). Translatotron 2: Robust direct speech-to-speech translation. arXiv preprint arXiv:2107.08661.
Jia, Y., Weiss, RJ, Biadsy, F., Macherey, W., Johnson, M., Chen, Z., & Wu, Y. (2019). Direct speech-to-speech translation with a sequence-to-sequence model. arXiv preprint arXiv:1904.06037.






