
[Convergence Research Team, Jihyun Song]
Deep Natural Language Processing for LinkedIn Search Systems
Recently, while studying Rasa Open Source, I am feeling how effectively the structuring and optimization design of chatbot systems is applied. The design and extraction of intents and entities are also very important. This is no different in the field of search engines. There is an interesting paper in the search, so I would like to briefly review it.
One of the main purposes in natural language processing is to extract structured information from user messages. A search engine extracts information from a user's query and provides an answer tailored to that query.
This paper introduces how to make a search engine efficient and robust by dividing it into 5 components, and also introduces how to use important intents and entities in chatbots.
In order to make a search system robust, there are three important things to consider: latency, robustness, and efficiency of the search. In order to improve the performance of these three systems, in this study, experiments were conducted in a fixed order through the systematic structure of five systems.
5 search engine components
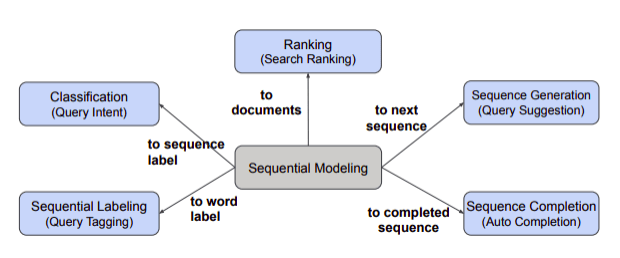
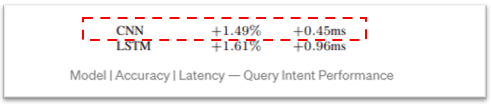
Classification (Query Intent) — As anyone who has used LinkedIn knows that, they use a lot of search terms with a big meaning, such as job openings, job search, and help center searches. First classify the intent of the query by breaking it down by term. In this process, the methodology CNN and LSTM models are used to conduct research, and among them, CNN with the lowest latency is selected and used.
Sequential Labeling (Query Tagging) — Tagging to create new queries that create better search results by creating entities that fit your intent. CRF, SCRF(current system), LSTM-SCRF model was used.
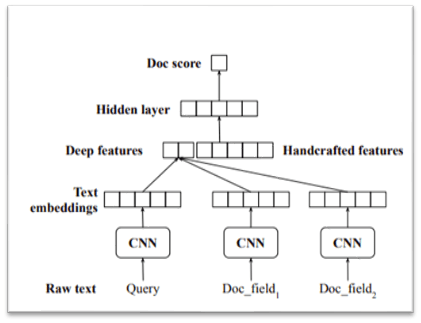
Ranking (Search Ranking) – Identify and reorder the most efficient and higher click-through rates. Predict the score of the document by using CNN first and then adding manual features later.
Sequence Generation (Query Suggestion) — requires that the input query and the reconstructed query have at least one common word, determines the frequency and reconstruction of search terms to determine what people were looking for, what they were searching for, etc. give. However, this method takes a long time and provides it in parallel with the search result ranking. After that, I was able to save time.
Sequence Completion (Auto-Completion) — Since most of the time taken by the query auto-completion function comes from normalization, this study saves time by exporting non-normalized weights.
Search engine overall system configuration diagram
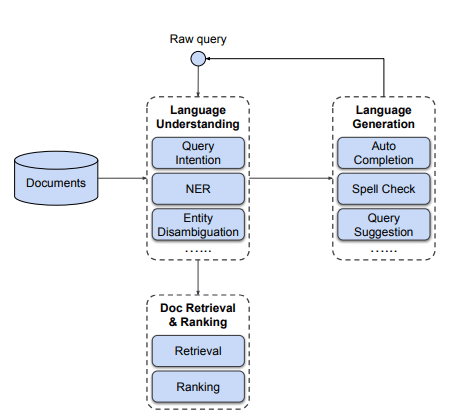
When a query comes in, the search engine operates in the following order.
- Language Understanding: Identify and process other details in a way that understands the intent of the query, disambiguates entities, and adds a few missing pieces.
- Language Generation: It goes through the process of language generation by suggesting auto-completion, spell check, and query.
- Doc Retrieval & Ranking: Calculates by searching multiple documents and ranking the most important among them (such as user click-through rate).
In this paper, it is said that Deep NLP is capable of paraphrasing by generating natural language and richly paraphrasing, so that it has high performance in terms of accuracy.
We are also proposing various methods to overcome the biggest issue in search engines, waiting time.
The alternatives are algorithm redesign, parallel computing, pre-trained embeddings, and applying two-path ranking calculations.
In addition, for robustness of search, we propose a method of using manual features along with denoising of training data and deep learning techniques.
Creating a high-performance search engine through five components is the contribution of this thesis, and if you identify and apply the characteristics of each component, it will be possible to use it for inputting information into chatbots or importing external knowledge.
thesis : https://arxiv.org/pdf/2108.08252.pdf
References: https://towardsdatascience.com/deep-natural-language-processing-for-linkedin-search-systems-6d136978bcfe






