
[가상인간연구팀 황준선]
TPU 소개
TPU(Tensor Processing Unit)는 Google에서 발표한 텐서 연산에 특화된 하드웨어입니다. TPU는 인공지능 모델을 학습시킬 때 필요한 행렬 곱 연산을 가속화하여 기존 GPU에서 학습시킬 때보다 더 빠른 학습 속도를 보인다고 알려져 있습니다.
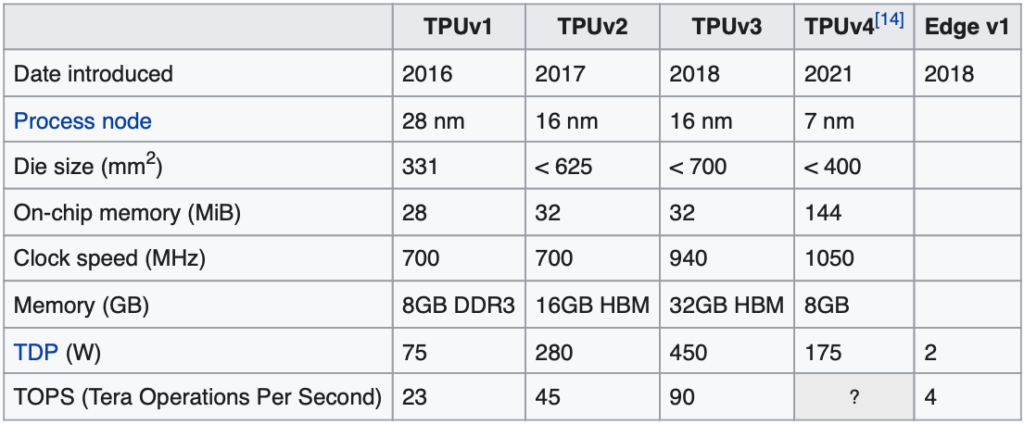
현재 TPU는 v4까지 출시되었으며, 스펙은 아래와 같습니다. 현재 GCP(Google Cloud Platform)에서는 TPU v3까지 사용가능하며, v4는 담당자 문의를 해야합니다.
TPU 학습 환경 설정
TPU를 통한 학습은 보통 GCS(Google Cloud Service)에 TFRecord 파일을 업로드한 후, TensorFlow+Keras를 통해 모델을 학습시키는 것이 최적화된 방법이며, 가장 좋은 학습 속도를 보입니다. PyTorch를 지원하긴 하지만, TensorFlow를 사용했을 때와 비교 했을 때, 학습 속도 면에서 차이가 납니다. 따라서 이번 포스트에서는 TensorFlow를 기준으로 학습 환경을 설정하려고 합니다.
포스트를 이어나가기 앞서, 필요한 변수나 함수 중 그 의미가 명확한 경우엔 해당 코드는 일부 생략되었습니다.
TPU 연결
TensorFlow 2.0 이상 버전에서는 tf.distribute.TPUStrategy() 객체를 이용하여 TPU를 사용할 수 있습니다. 이는 tf.distribute.Strategy()와 같이 분산 학습을 설정하는 정책이라고 생각하면 됩니다. 또한, TPU와의 connection도 이 객체를 통해 다음과 코드와 같이 가능합니다. 추가로 자신의 TPU 주소가 필요합니다.
tpu = tf.distribute.cluster_resolver.TPUClusterResolver(tpu=tpu_address)
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.TPUStrategy(tpu)데이터셋 준비
TFRecord를 GCS에 저장하고 이를 불러와서 사용합니다. GCP의 DataFlow를 이용하여 TFRecord를 만드는 방법에 대해서는 추후 포스트에서 다루도록 하겠습니다.
def parse_example(serialized_example):
data_fields = {
"input_ids": tf.io.VarLenFeature(tf.int64),
}
parsed = tf.io.parse_single_example(serialized_example, data_fields)
inputs = tf.sparse.to_dense(parsed["input_ids"])
inputs = tf.cast(inputs, tf.int32)
return inputs
def input_fn(tf_records,
max_epochs,
batch_size,
is_training,
padding_values,
buffer_size=10000):
if type(tf_records) is str:
tf_records = [tf_records]
dataset = tf.data.TFRecordDataset(tf_records, buffer_size=buffer_size)
if is_training:
dataset = dataset.shuffle(buffer_size=buffer_size)
dataset = dataset.repeat()
dataset = dataset.map(parse_example, num_parallel_calls=tf.data.experimental.AUTOTUNE)
dataset = dataset.padded_batch(batch_size, padding_values=padding_values)
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
return dataset
train_dataset_size = len(list(tf.data.TFRecordDataset(train_data_paths)))
steps_per_epoch = train_dataset_size // batch_size if train_dataset_size / batch_size == 0 else train_dataset_size // batch_size + 1
per_replica_batch_size = max(batch_size // strategy.num_replicas_in_sync, 1)
train_dataset = strategy.experimental_distribute_datasets_from_function(lambda _:
input_fn(train_data_paths, batch_size=per_replica_batch_size, max_epochs=max_epochs, is_training=True, padding_values=tokenizer.pad_token_id))
train_iterator = iter(train_dataset)데이터셋을 준비할때 (전체 학습 데이터의 샘플 개수, 1에폭당 총 스텝, replica별 배치 사이즈) 이렇게 3개의 상수 값이 필요합니다. 그리고 strategy.experimental_distribute_datasets_from_function() 함수를 이용해 dataset을 반환하는 함수를 감싸주는 형태로 학습 데이터 로더를 만듭니다. 이 함수는 keras의 model.fit() 함수를 이용하여 학습할 경우 사용하지 않고, dataset을 반환하는 함수만 선언하고 사용해야 합니다. parse_example() 함수는 TFRecord의 각 example을 data_fields에 맞게 파싱하는 기능을 합니다. 예시를 간단하게 하기 위해 ‘input_ids’ field만 넣었지만, ‘attention_mask’, ‘token_type_ids’, ‘position_ids’ 등 모델 forward에 필요한 다양한 field를 파싱하여 return할 수 있습니다. 이렇게 한다면, train_dataset은 iter() 함수를 통해 데이터 로더의 역할을 할 수 있습니다.
모델 준비
모델은 HuggingFace의 transformers에서 TensorFlow와 연동되는 어떤 모델도 불러와서 사용이 가능합니다. TPU에서 학습을 하기 위해서 Strategy.scope() 안에 모델과 optimizer, loss를 포함한 여러 metric이 선언되어야합니다.
from transformers import TFGPT2LMHeadModel, GPT2Config
with strategy.scope():
model_config = GPT2Config()
model = TFGPT2LMHeadModel(model_config)
optimizer = tf.keras.optimizers.AdamW(learning_rate=learning_rate)
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(
'train_accuracy', dtype=tf.float32)모델 학습
학습 방법은 크게 2가지 방식이 있습니다. keras의 model.fit() 함수를 활용하는 방법과 tf.GradientTape()을 이용한 사용자 정의 학습 루프를 활용하는 방법입니다. HuggingFace의 TF모델들도 model.fit() 함수를 사용할 수 있습니다. 하지만, 이 방법은 모델의 입력으로 들어가는 파라미터가 한정적이기 때문에 BERT처럼 attention mask 정보 등을 같이 입력으로 넣어줘야하는 모델을 학습시키는 데에 한계가 있습니다. 따라서 tf.GradientTape()을 활용하는 방법을 설명해드리겠습니다. 이 두개의 차이점은 TPU 사용에 자세히 설명 되어있습니다.
@tf.function
def train_step(iterator):
def step_fn(batch):
input_ids = batch[0]
with tf.GradientTape() as tape:
outputs = model(input_ids)
logits = outputs.logits
loss = tf.keras.losses.sparse_categorical_crossentropy(
labels, logits, from_logits=True)
loss = tf.nn.compute_average_loss(loss, global_batch_size=batch_size)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(list(zip(grads, model.trainable_variables)))
training_loss.update_state(loss * strategy.num_replicas_in_sync)
training_accuracy.update_state(labels, logits)
strategy.run(step_fn, args=(next(iterator),))
for epoch in range(max_epochs):
print('Epoch: {}/{}'.format(epoch, max_epochs))
for step in range(steps_per_epoch):
train_step(train_iterator)
print('Current step: {}, training loss: {}, accuracy: {}%'.format(
optimizer.iterations.numpy(),
round(float(training_loss.result()), 4),
round(float(training_accuracy.result()) * 100, 2)))
training_loss.reset_states()
training_accuracy.reset_states()후기
TPU를 사용해봤을 때 확실히 빠른 속도를 체감할 수 있었습니다. 기존에 많은 연구자분들이 활용하는 HuggingFace 플랫폼의 다양한 모델들을 가져와 공식적으로 권장하는 방법들로 학습할 수 있다는 사실은 매력적이라고 생각합니다. TPU v4는 v3보다 2배 가까이 성능이 높아지는 만큼, GCP에 보급화된 이후 학습 속도 및 추론 속도가 기대됩니다.






