
[가상인간연구팀 전동준]
언어 모델(Language Model, LM)은 단어나 문장을 확률적으로 예측하는 모델입니다. 통계적으로 다음에 등장할 단어들을 모델링하는 전통적인 방식에서 최근에는 딥러닝 기반의 언어 모델들이 많이 연구되고 있습니다. BERT, GPT-3 같은 많은 데이터와 오랜 시간 학습한 사전 훈련 언어 모델(Pretrained Language Model, PLM)들이 다양한 Task에서 높은 성능을 보여줌에 따라서 점점 더 많은 데이터를 학습시킨 PLM들을 다양한 곳에서 만들고 사용하고 있습니다.
Pretrained Language Model
PLM은 기본적으로 굉장히 많은 데이터와 많은 학습 가능한 파라미터를 가진 모델입니다. PLM은 방대한 데이터로부터 학습하여 언어의 맥락을 기본적으로 이해하면서 많은 Task들에서 사용될 수 있습니다. 하지만 모델이 크고 아무 튜닝없이 바로 사용할 수는 없습니다. 크고 좋은 도구이지만 좀 더 작은 단위의 일을 할 때는 각 Task에 맞게 튜닝하는 방법들이 필요합니다.
GPT-3 Generation
PLM을 다양한 자연어 Task에 사용하기 위해 In-Context learning 방식을 사용합니다. GPT-3 모델에 각 Task를 설명하는 정의나 예시를 넣으면 잘 학습된 LM 모델이 Task에 대한 맥락을 이해하여 더욱 높은 성능을 낼 수 있는 것이죠. Task에 대한 설명과 예시 단어들(프롬프트)을 적절하게 줌으로써 소설, 뉴스, 블로그같은 콘텐츠들을 사람같이 만들어낼 수 있고, 최근에는 학술 논문도 만든 예가 있었습니다. 기사링크
PLM 자체를 학습하는 것은 리소스가 크고 GPT-3같은 모델들은 오픈되어 있지 않아 모델 자체를 제어하기 어렵습니다. 그래서 모델에 줄 수 있는 프롬프트를 제어하는 프롬프트 엔지니어링에 대한 테크닉이 많이 연구되었습니다. 아래 그림처럼 Task에 대한 몇 개의 예제(Few-Shot)를 프롬프트로 주면 GPT-3는 마지막 A: 다음에 올 단어를 생성하는 방식입니다.

GPT-3 QA 프롬프트 예제
Prompt Engineering
PLM을 Downstream Task에 맞게 사용하기 위해서는 적절한 프롬프트 예시를 잘 넣어주어야 합니다.
GPT-3 보다 더 많은 데이터와 파라미터를 가진 모델들이 나왔지만, GPT-3는 여러 서비스들에 실제로 사용되고 있습니다. 하지만 GPT-3 모델 자체가 공개되어 있진 않고 OpenAI에서 API 형태로만 제공하고 있기 때문에 적절한 프롬프트 포맷을 이용하여 효과적으로 사용할 수 있게 만드는 프롬프트 엔지니어링에 관한 연구들이 많이 이루어지고 있습니다.
그중에 구글에서 6월에 발표한 논문중에, 간단한 테크닉이지만 복잡한 수학 문제나 추론 문제를 풀 때 프롬프트 예시로 추론의 과정을 넣어주면 언어 모델도 해당 추론을 이해하고 같은 방식으로 답변을 추론하는 방법을 제시했습니다. 어떻게 보면 인간의 뇌를 완전히 사용하지 못하고 10% 정도만 사용한다고 하는 것처럼, 거대 언어 모델의 진정한 능력을 완전히 사용하고 있지 못했지만, 이런 방법들을 통해 언어 모델의 사용량을 높일 수 있게 제어하는 방법처럼 생각됩니다.
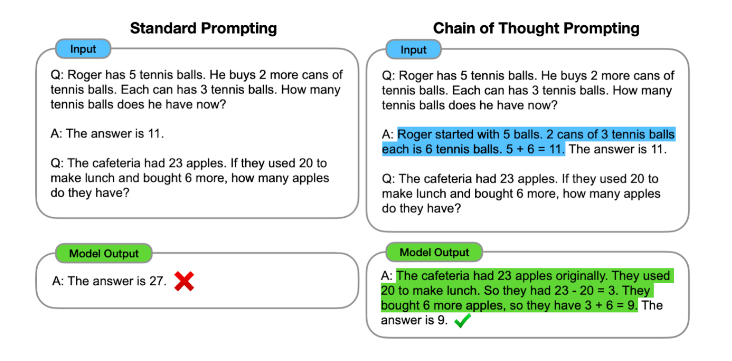
구글에서 발표한 프롬프트 엔지니어링 방식. 추론 과정을 퓨샷 예제로 넣어줌으로써 더욱 정확한 답을 추론할 수 있다.
논문에서는 이런 간단한 방식으로 수학 문제를 푸는 Task에서 높은 성능을 낼 수 있다고 말하고 있습니다. LaMDA(Language Model for Dialogue Applications)와 PaLM(Pathways Language Model) 모델은 구글에서 각각 작년 5월, 올해 4월에 발표한 PLM들로 해당 모델들도 이런 프롬프트 엔지니어링 방법으로 성능을 높일 수 있다는 것을 말해주고 있습니다. 모델의 파라미터가 커질수록 기존 프롬프트 방식과 성능 차이가 더 비교되었는데, 인공신경망 모델의 숨겨진 능력을 더욱 이끌어내는 느낌입니다.
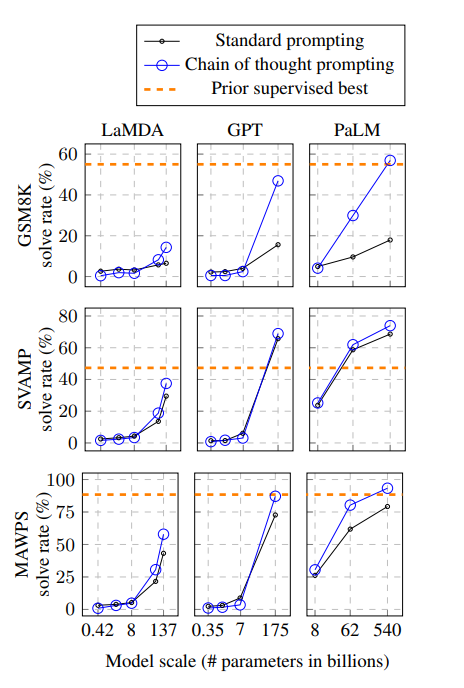
Chain of Thought 방식을 사용하면 기본 프롬프트 방식보다 성능이 높다.
With Search Engine
방대한 양의 데이터를 학습하였더라도 언어 모델의 한계는 있습니다. 사람들이 사용하는 언어는 끊임없이 바뀌고, 데이터의 지식적인 측면도 가변적입니다. 매일 변화하는 코로나 확진자 수나 정세같은 것들을 언어 모델이 학습하기는 어렵습니다.
메타 AI(페이스북 AI)에서는 검색엔진을 이용하여 LM의 한계를 극복하는 방법을 제시했습니다. 이전 LM을 이용한 대화 모델인 BlenderBot 2에서도 외부 지식을 이용하여 지식 대화를 더 잘할 수 있는 모델을 공개하였습니다. 이보다 더 좋은 성능의 SeeKeR 라는 언어 모델은 주어진 프롬프트에서 1) 검색 쿼리를 만들고 2) 검색엔진에서 문서를 검색한 후에 3) 그 문서를 프롬프트 형태로 다시 생성에 사용하는 방식으로 작동합니다.
OpenAI의 WebGPT 도 같은 방식으로 검색 엔진을 활용하여 언어 모델이 학습하지 못한 외부 데이터에 대한 지식을 생성해낼 수 있습니다.
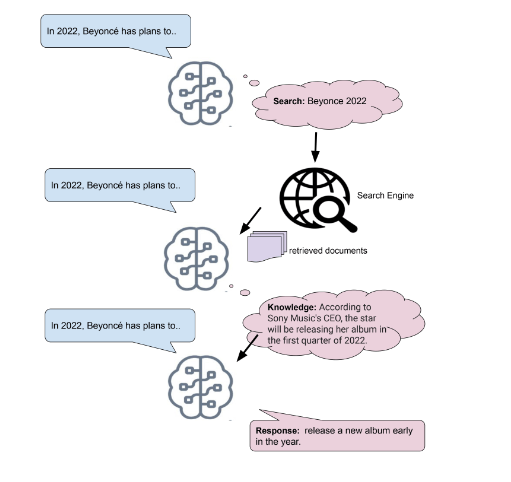
Meta AI(Facebook AI)에서 제시한 SeeKer. 검색엔진을 이용하여 외부 문서를 가져와서 LM의 지식을 보충하는 방식,
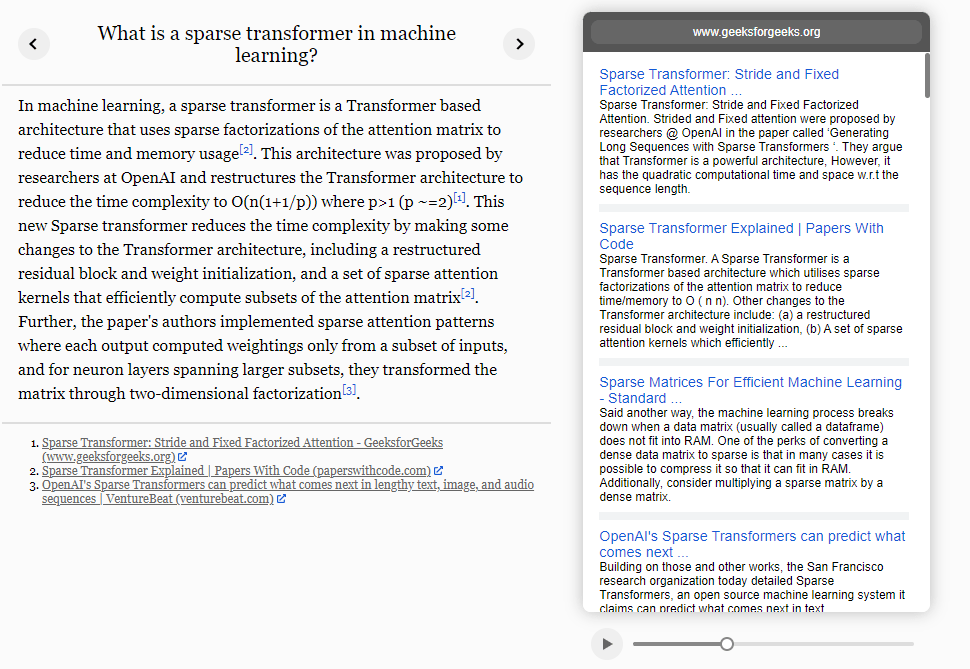
WebGPT 작동방식 화면 캡쳐
거대 언어 모델들은 성능이 뛰어납니다. 하지만 Task-Specific한 일들을 “실제로” 하기 위해서는 언어 모델을 쥘 수 있는 손잡이를 바꿔주어야 각 Task에 맞는 일들을 잘할 수 있습니다. 아직은 좋은 언어 모델을 만드는 것은 빅테크 기업들이 주도하고 있고, 중소 규모의 연구자들이 만들기는 어렵습니다. 그렇기 때문에 거대 언어 모델을 효과적으로 사용할 수 있는 이런 방법론과 테크닉들이 더욱 많이 연구될 것 같습니다.
Reference
https://openai.com
https://ai.googleblog.com/2022/05/language-models-perform-reasoning-via.html
https://parl.ai/projects/seeker/






