
소개글
[선행AI기술팀 신영준]
과거에 비해 인공지능 기술은 놀라운 정도로 발전을 거듭하여, 이제는 비전문가도 어느 정도 노력만 한다면 쉽게 원하는 목적성을 띈 모델을 만들 수 있게 되었다.
그러나 이미지 또는 자연어처리에 비해 음성 도메인은 보다 폐쇄적이며 예전보다 쉬워졌음에도 전문가적 지식이 더 필요한 분야라고 생각한다.
음성 관련 연구를 진행하는 연구자로서 보다 비전문가와의 소통 및 협력 측면에서 도움이 되길 바라는 마음에 최대한 쉽게 풀어쓰고자 한다. (쉽게 쓰다보니 어느정도 주관이 들어가 잘못된 정보가 있을수도..)
음성 도메인에서도 세부적으로 여러 가지 분야 (예: 음성 변조/ 음성 합성/ 화자 분리/ 음성 인식 등)가 존재하지만 연구 분야인 합성에 대해서 중점적으로 서술할 것이다.
음성 변조와 음성 합성은 무엇이 다를까?
음성합성은 TTS[Text-to-Speech], 음성변조는 VC[Voice Conversion]라고 불리는데 사람마다 이 둘을 정의하는 바가 다를 순 있겠으나 작성자는 다음과 같이 정의한다.
- 음성 변조 : 음성을 입력으로 원하는 목소리로 변환하는 기술
- 음성 합성 : 텍스트를 입력으로 원하는 목소리로 합성하는 기술
결국 두 분야의 차이는 단순하게 입력의 종류가 다른 것으로 해석할 수 있지만 사실은 이것으로 인해 기술의 목적성이 크게 바뀐다.
음성을 들어보면 단순하게 이 음성의 성별이 무엇인지, 깊게 나아가면 누구의 목소리인지 판별할 수 있는 화자와 연관되는 요소를 포함한다.
그러나 텍스트는 그러한 정보들이 거의 없다시피하여 존댓말/반말, 말투에 대한 일부 정보들만 존재할 뿐이다. 이에 따라 글만 봤을 때 어떤 감정이 담겨 있는지 판단할 수 없기 때문에 이를 보다 잘 나타내고자 이모티콘 등의 기능이 생겨났다고 생각한다.
이것을 보다 분야화하자면
- 음성 합성 : 화자 정보가 없는 텍스트로부터 화자 정보를 주입 (injection).
- 음성 변환 : 화자 정보가 포함된 음성으로부터 다른 화자로 변환하는 스타일 변환 (Style transfer) / 화자 정보 분리 (Disentangle) 및 재합성.
위와 같이 나타낼 수 있어서 두 모델의 구조는 다를 수 밖에 없고 이를 학습함에 있어서 데이터 구조도 달라지게 된다.
또한 음성 합성을 하기 위한 데이터셋은 화자의 음성과 그에 상응하는 텍스트 즉, paired data가 필요하나 변조는 단순하게 화자의 음성 데이터들만 있어도 가능하다는 점이 다르다.
물론 연구 기법과 어느 정도의 제어력(Controllability)를 원하는 가에 따라서 데이터 포맷 또한 달라지게 되는데 정론에 가까운 것만 서술할 예정이다.
TTS: Text-to-Speech
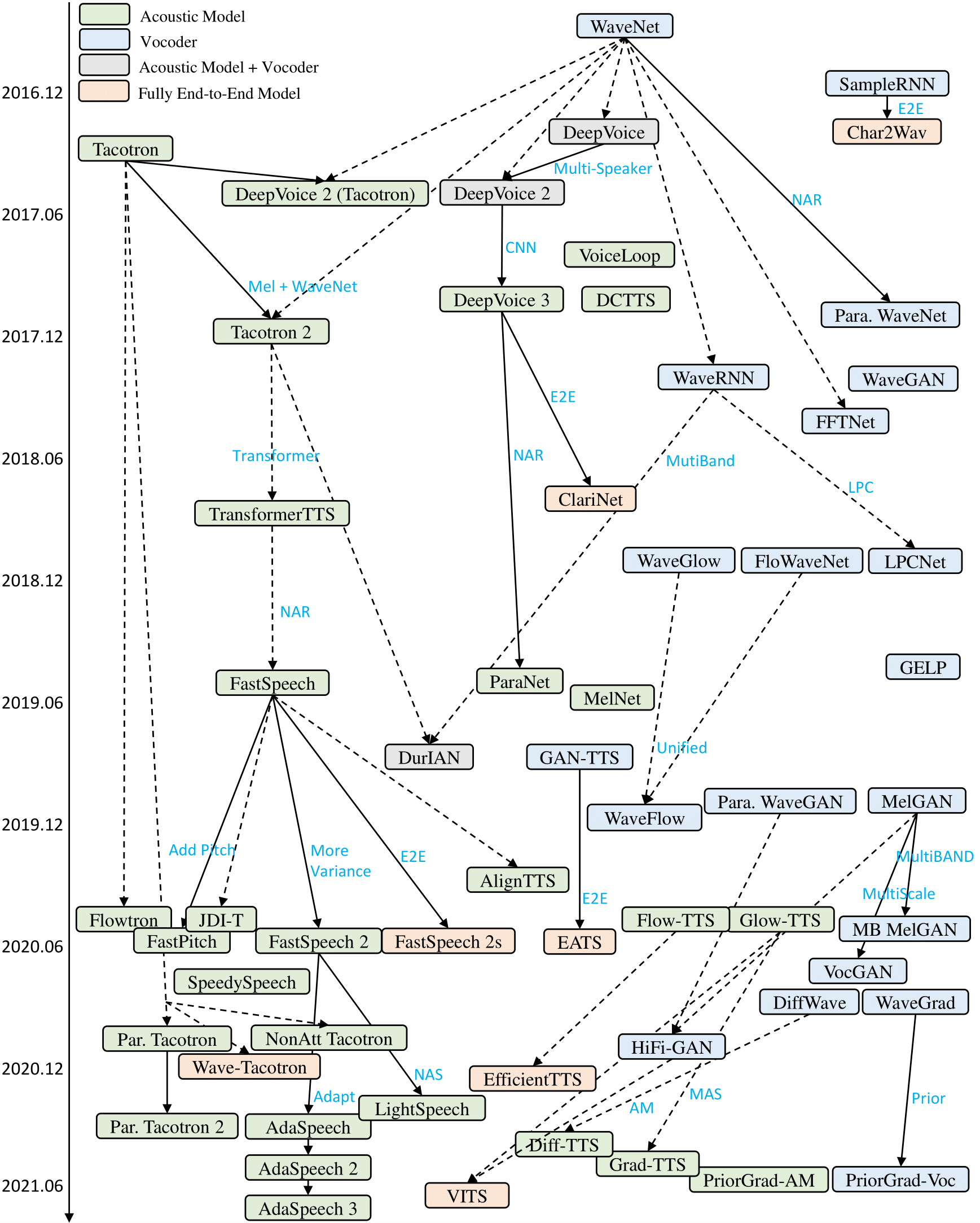
16년도 WaveNet[arXiv:1609.03499], 17년도 Tacotron[arXiv:1703.10135]을 기점으로 딥러닝 기반의 음성 합성 TTS 모델들이 현재까지 꾸준히 발전해 오고 있다.
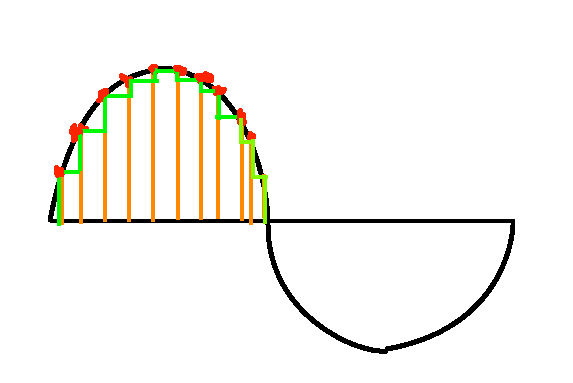
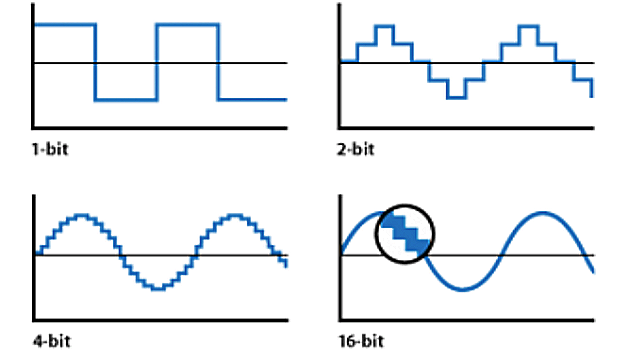
자연에 존재하는 발화 신호는 기계 신호로 양자화하는 과정에서
- 그림 1 : 1초에 몇 개의 샘플을 획득할 것인지의 Sample Rate(이하 SR)
- 그림 2 : 샘플을 몇 가지 수로 나타낼 것인지의 Bit Rate
가 등장하는데, 간단하게 예전 공중전화 음질에서부터 게임/유튜브 이를 넘어서기 까지를 결정하는 요소이며 높을 수록 좋다는 것만 이해해도 충분하다.
그렇다면 자연스럽게 위의 두 숫자는 높을수록 좋으므로 애초에 높게 설정하여 음성을 만들면 “예전에도 유튜브 음질이 가능했겠네”란 의문이 들 것이다.
하지만 당연하게도 불가능한 이유가 있었으니 그 이유는 다음과 같다.
- 1초에 2만여개 프레임을 포함하는 sparse input으로부터 context를 추정할만큼 넓은 receptive field를 가진 아키텍처의 부재 (WaveNet[arXiv:1609.03499] 이전)
- 음소의 발화 시간은 대략 20~50ms으로 1초에 20~50여개 정도이지만, 음성은 1초에 2만에서 4만여개 프레임으로 1k배 정도 길이 차 사이의 관계성을 학습시키기 어려움
- 고주파대역으로 갈 수록 임의성이 짙어져 확률 모델 도입 없이 고주파 정보의 구현이 어려움
보다 쉽게 해석하자면 하드웨어의 발전 및 기술의 발전 모두 허용치 이하였기에 힘들었으나 멋진 연구자들의 노력으로 인하여 가능해졌다.
어떤 아이디어가 바탕이 되었을까?
바로 Spectral feature라는 중간 매개를 통해 원하는 목적성을 띈 모델들의 결합을 성공시켰고, 아래와 같이 2 Stage(Acoustic, Vocoder)로 나누어 고품질의 음성합성을 가능토록 했다.
- Acoustic (Stage 1): 텍스트에서 spectral feature을 합성
- Vocoder (Stage 2): spectral feature로부터 음성을 복원
Spectral feature란 무엇일까?
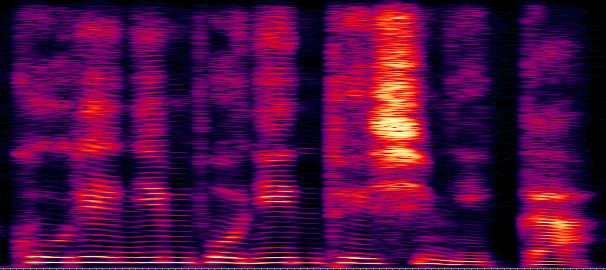
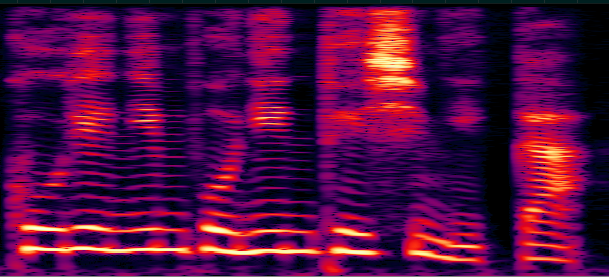
단순하게 아무 feature을 매개체로 두 모델의 결합을 하는 것은 당연하게도 불가능하며, 교과 과정 중 배운 Fourier Transform을 이용하여 시간대역을 주파수대역으로 바꾸고
여러 수학적 요소를 담아 만들어진 Spectral feature는 사실 인간의 청각 체계를 모사화했다고 보면 된다.
신기하게도 청각체계는 음의 세기와 높낮이에 모두 log-scale로 반응한다. 신호의 세기가 N배 커지더라도, 실제로는 보다 적게(logN 정도로) 인식하는 것이다.
이를 반영하여 인간이 실제로 듣는 신호의 세기와 높낮이 대역을 강조하기 위해 수학적 연산을 통해 얻은 그림 3을 인간의 청각 체계의 특성을 따라 그림 4로 치환하여 위의 문제를 해결한 것으로 이를 간략하게 Mel-spectrogram 또는 log-mel spectrogram이라 일컫는다.
위의 수학적 연산의 종류와 방법에 따라 다른 Feature들을 도출할 수 있고, 이를 이용할 수도 있지만 대표적으로 Mel-spectrogram을 사용한다 (최근 추세는 자연어 분야의 발전으로 오디오 코덱을 활용한 기법들로 변경되었다. 보다 전문가적인 지식을 원할 경우 SoundStream, AudioLM들 참조).
자, 이제 위의 feature들을 가지고 어떻게 활용하여 고품질 음성합성이 가능해졌는지 Stage 1 Acoustic Model을 알아보자.
Acoustic Model이란?
Acoustic model은 텍스트에서 위에서 언급한 mel-spectrogram을 만드는 모델이며, 음성 분야는 다른 분야와는 다른 독특한 특성을 가진다.
- 발화 특성상 음소가 동일한 문장이어도 사람마다, 녹음마다 발화의 길이가 달라질 수 있어 음소만으로는 발화 길이의 추정의 어려움
- 텍스트와 발화 음성 모두 시간 축에 따라 정렬되기 때문에 둘의 관계성이 순증가(monotonic) 하는 특성을 띔
좀 더 쉽게 해석하자면
- ‘감사합니다’ 라는 문장을 발음하는 방법은 사람/감정/나이 등 여러가지 요소에 따라 매우 다르다.
- 감을 발음한다음에 사를 발음하지 감다사합니 처럼 읽지만 않는다. 물론 이래도 이해되는게 한국어의 MAGIC.
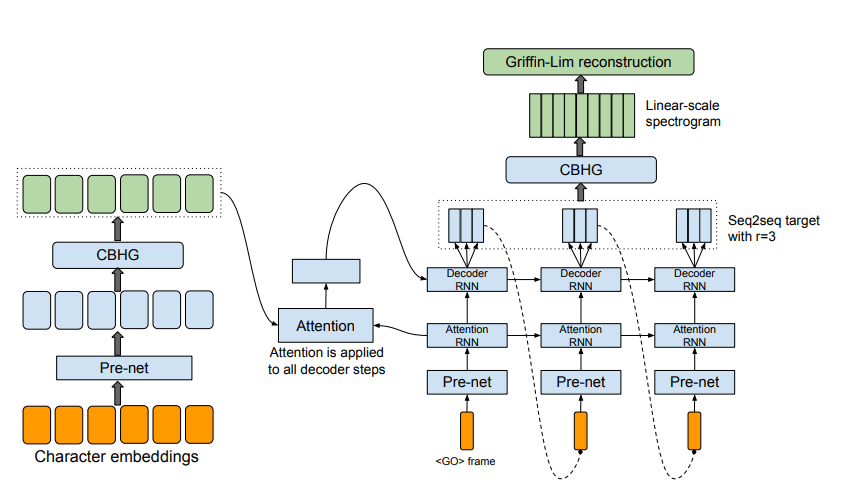
그림 5을 보면 Tacotron의 구조가 보인다.
크게 Attention을 중심으로 왼쪽과 오른쪽으로 나뉘는데, 왼쪽을 Encoder 오른쪽을 Decoder라 칭한다.
즉, TTS는 Encoder, Attention, Decoder의 결합으로 만들어진 것이며 이 구조는 정말정말 다양해졌고 현재 사장된 기술이기에 각 모듈에 대해 설명하기 보단 아이디어 중심으로 서술하고자 한다.
글자가 있을 때 글자하나하나는 의미를 거의 내포하고 있지 않으나 이것이 단어 단위가 되는 순간 그 의미가 부여되기에 그 관계성을 학습하는 것이 핵심이다.
따라서
- Encoder: 글자들의 조합에 따른 정보를 함축시키는 것이 역할
- Attention: 그 글자들의 정보가 최종 출력인 Spectral Feature와 어떤 연관성을 갖는가
- Decoder: Spectral Feature의 다음 시간(정확하게는 Frame이다)에는 어떤 Feature가 나올 것인지 예측
로 나뉘며, 이에 따라 학습 데이터는 위에서 언급한 바와 같이 텍스트와 음성을 수학적으로 재조립한 Spectral Feature가 필요한 것이다.
그림 5의 Tacotron시절에는 초록색 글씨의 Griffin-Lim이라는 전통적인 기법으로 이 Feature을 음성화하였는데 기계음이 많이 섞여서 음질이 좋지 못하였기에 Spectral Feature을 음성화할 수 있는 방법이 대두되기 시작했다 (실제로는 Vocoder인 Wavenet(2016)이 Tacotron(2017)보다 먼저 나왔음).

Vocoder Model이란 무엇인가?
보코더는 음성을 압축/복원하는 기술을 통칭한다. TTS에서는 algorithmic 하게 구해진 spectrogram(mel-scale)을 음성으로 복원하는 모델을 이야기한다.
단순히 STFT만을 취했다면 발화 신호 특성상 iSTFT만으로도 충분한 음성을 복원해낼 수 있지만, mel-spectrogram 변환 과정에서
- 주파대역별 세기를 측정하기 위해 실-허수 신호를 실수 신호로 축약하는 Absolute 연산
- 500~1000여개 bins를 80~100개로 압축하는 filter bank 연산
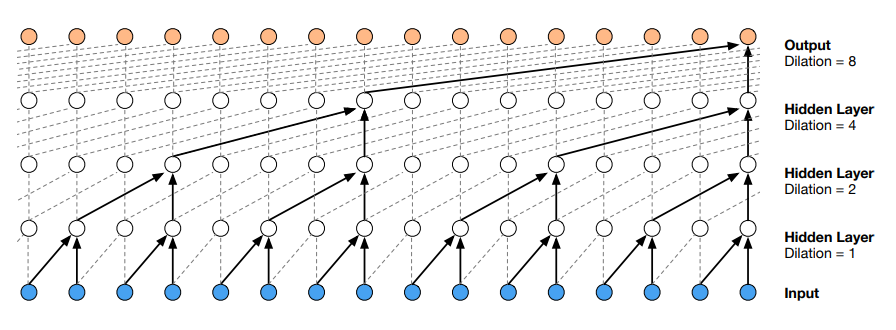
의 2가지 손실 압축을 거치기에 알고리즘을 이용한 복원에는 한계가 존재할 수 밖에 없었고 이를 해결하고자 Wavenet이 나왔는데 속도가 너무 느려서 현재는 사용하지 않으나, Vocoder의 선조격인 모델이다. 그 논문에서는 초당 2만여개 프레임을 감당할만한 receptive field을 확보하기 위해 Dilated convolution을 도입하였고, 그림 7과 같이 일정 부분을 건너뛰어 계산하여 연산량을 크게 줄이며 receptive field를 늘렸다.
마치며
이상으로 2stage TTS의 기초에 대해서 간략하게 설명하였다.
2016년, 2017년 논문을 기술하다보니 현재와는 맞지 않는 부분도 상당수 있었으나 그 근간을 설명하고자 기술한 글이기에 다소 이해를 돕기 위한 정확하지 않은 정보가 있더라도 이해바란다.
2stage의 고질적인 단점을 해결하기 위해 고품질의 1stage방법론, 하나하나의 프레임을 예측하는 방법(Auto-regressive)대신 모든 프레임을 한번에 예측하는 방법(Parallel Model), Neural Audio Codec을 활용하여 Spectral feature을 대체하는 Token활용 방법론 등 현재도 쉴 새 없이 훌륭한 연구 결과들이 나오고 있다.
또한 기존에는 최소 1시간 이상의 Paired Data가 필요했으나 현재는 단 몇초의 데이터만로도 어느정도 원하는 음성이 만들어 지는 시대가 되었다.
예전에 비해 보다 쉬운 접근성과 점차 코드를 공개하는 쪽으로 방향 선회가 된만큼 비전문가들도 일반적인 톤의 음성뿐만 아니라 노래하는 음성도 쉽게 만들 수 있음으로 재밌게 즐기길 바란다.
- 전에 같이 연구했던 연구자의 블로그 글을 정제 추가 및 주관대로 해석한 글임
Reference
1. https://revsic.github.io/blog/alignment/
2. https://arxiv.org/pdf/2107.03312.pdf
3. https://arxiv.org/pdf/2209.03143.pdf
4. https://arxiv.org/abs/1703.10135
5. https://arxiv.org/abs/1712.05884






