
I've heard stories that if you get special training, you can see what you're talking about from just the silent movement of your lips. The technology called as Lip2Wav extracts visual features by ConvNet, then the attention-based speech decoder generates mel-cepstrum from them. After that, vocoder is added to synthesize a voice signal. The result is quite interesting. (There is a demo video in the link) The code and the dataset are also released.
I was amazed when I saw MIT's Speech2Face, a technology that generates faces from voice signals, but Lip2Wav is also fun. Both studies have an encoder-decoder structure, and it is expected that various studies in the form of A2B for various inputs and outputs will continue to emerge. Below is Lip2Wav's project page.
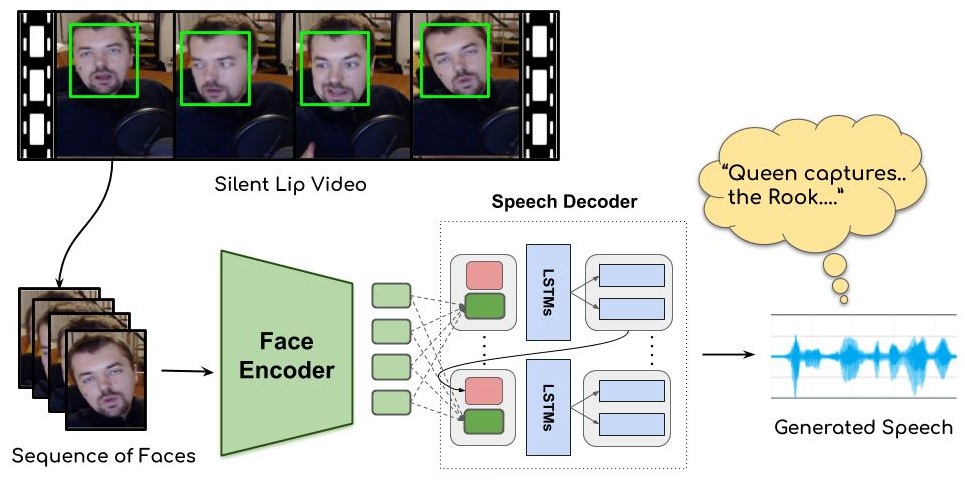
In addition, the author has released the code and training data. I also attach a link to this.








