
[Prior Research Team Lee Jung-woo]
Recent reinforcement learning has shown that AI agents can dominate human performance in a variety of tasks. However, the unlearned AI agent has the disadvantage that it requires a lot of time to learn and the generalization performance for various tasks is poor compared to humans. On the other hand, humans, unlike AI agents, adapt well to new situations and have the ability to continue learning new knowledge. Continual Learning was born by referring to the ability of these people. In this article Towards Continual Reinforcement Learning: A Review and Perspectives Through (Khetarpal et al., 2020), I would like to introduce Continual Reinforcement Learning that fits well with the real world situation.
- Reinforcement Learning
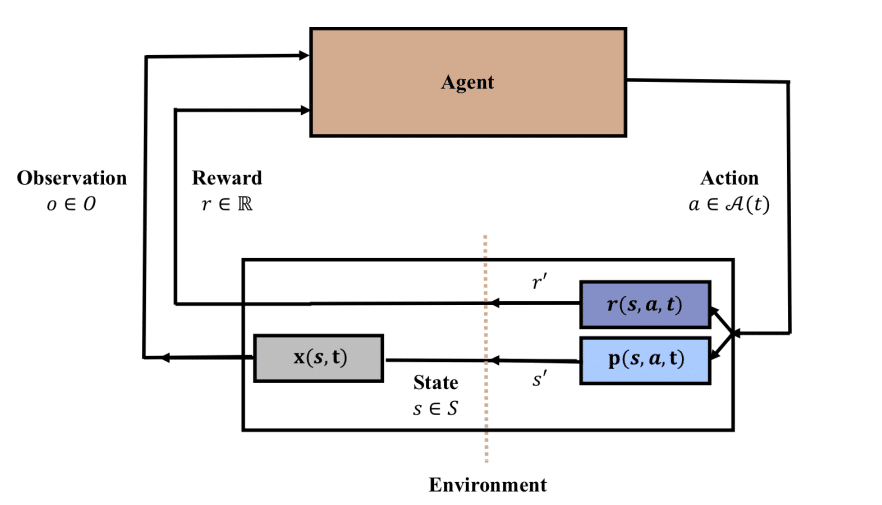
The figure above shows the basic form of reinforcement learning. The authors of the paper talk about the time-dependent part of the state, action, and reward of reinforcement learning. If the environment is an infinite scenario that cannot go back to the past again, it can be viewed from a non-stationary point of view because the state that has already passed in the past by the standard of the real world cannot go back. This natural passage of time and the conditions for maintaining past abilities are the best conditions for experimenting and verifying Continual Learning.
- Continual Learning
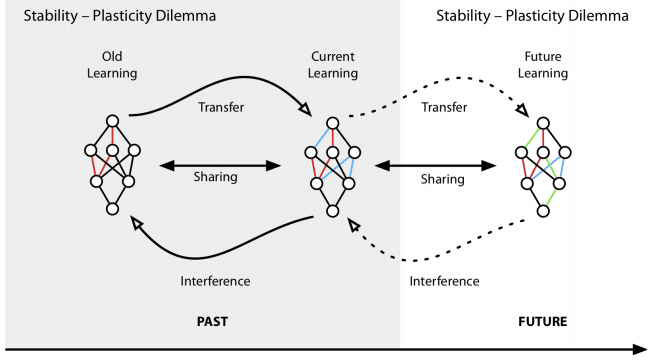
Continual Learning aims to solve the “stability-plasticity dilemma”. At the expense of plasticity for stability, you can keep what you learned in the past, but you can be weak for the newly learned knowledge. Conversely, focus on new knowledge, and Catastrophic Forgetting issues can arise. Maintaining the ability to learn from the past between stability and plasticity and enabling continuous new learning is the key to Continual Learning.
- Continual Reinforcement Learning
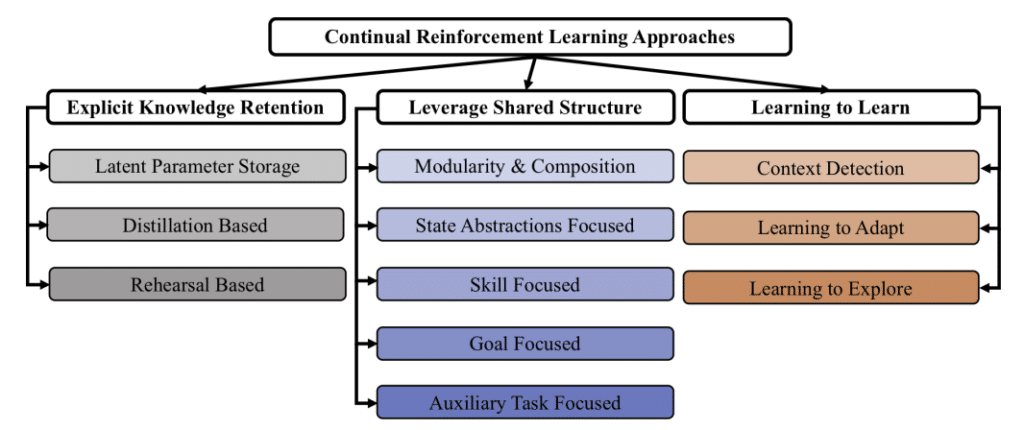
Continual RL has three main goals.
- Explicit Knowledge Retention: Maintains knowledge by preventing catastrophic forgetting that occurs during learning, increases stability, and ensures optimum plasticity.
- Leverage Shared Structure: In the case of an AI agent that continuously learns, the structural aspect to solve the problem and the solution obtained from the sub-problem solved in the past are reused, and are automatically used for planning, learning, and reasoning. Make good use of this shared structure.
- Learning to Learn: Finally, aims to learn how to learn itself. Basically, it has the same goal as meta-learning.
Through three main goals, we learn to learn how to learn and develop by grasping the shared structure of the acquired knowledge while maintaining the past knowledge like humans.
- Evaluating Continual Reinforcement Learning
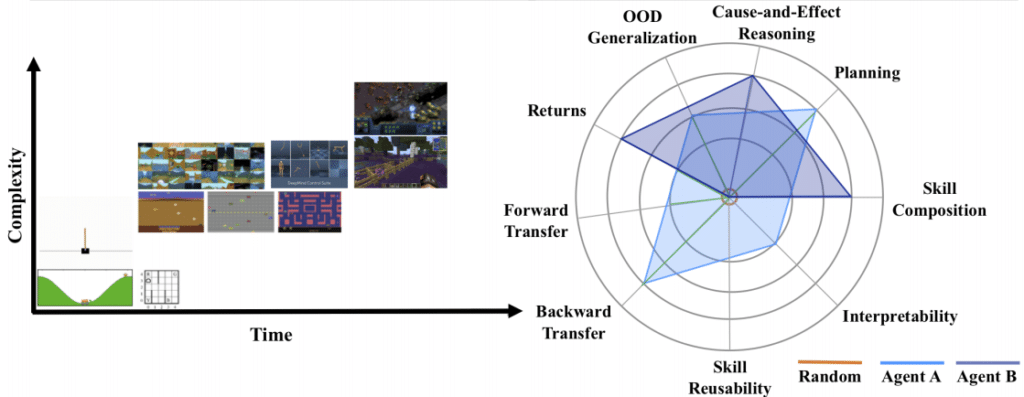
To evaluate the various aspects of Continual RL discussed earlier, the paper describes seven indicators for evaluating Continual RL agents.
- Catastrophic Forgetting (Forward and Backward Transfer): Evaluates whether an AI agent effectively uses previously acquired knowledge in a new related context (Forward transfer) whether it can improve the performance of similar functions previously learned in the current context Evaluation (Backward transfer).
- Skill Reusability: When encountering a new, unexperienced situation, evaluates whether you can reuse previously learned skills and create new ones.
- Interpretability: qualitatively evaluates learned representation, obtained behavior, value function, and policy and uses them to develop learning rates and scores.
- Skill Composition: Assess whether the agent is more effectively using what it has previously learned from this data.
- Planning: Evaluate whether you can effectively plan for the future using the knowledge you have acquired.
- Cause and Effect Reasoning: It is measured through causal analysis whether the agent is actually learning the rules and objects in the environment.
- OOD (Out of Distribution) Generalization: It is possible to predict the return through zero-shot and evaluate the generalization performance of the agent through the complexity of the sample.
In order to create a human-like learning process, there are various fields such as lifelong learning, online learning, and never-ending learning along with Continual RL introduced in this article. It would be nice to see if continual RL, a combination of continual learning that has recently emerged and reinforcement learning that surpasses human performance in some fields, will show another potential for growth.
- Reference
https://arxiv.org/abs/2012.13490






