
[Service Development Team Jeon Jeon Jeon]
ML-Agents, released by Unity, is an open source tool for creating virtual characters in game environments. You can create a game environment and learn NPC characters (Agents) that can operate in the environment through algorithms such as reinforcement learning. First released in 2017, v1.0 was released a year ago, and v2.0 was released last month with the ability to support training of multiple agents and more.
The toolkit, which was released as an open source, consisted of 18 example learning environments that were made for agents to move objects or move toward specific goals, and it provides a guide for creating new environments.

ML-Angets by default pytorch(https://pytorch.org) based on onnx(https://onnx.ai) to use the converted model in Unity. It supports examples in the Colab environment familiar to AI researchers, and is compatible with OpenAI's gym environment. Even if you do not have much knowledge about learning algorithms, you can use the latest implemented algorithms, and the guide documentation is well done.
Below, we tested the cooperative behavior training example newly added in v2.0. This is the Dungeon Escape environment, which is one of the examples of ML-Agents. In an environment with 3 agents and 1 dragon, the agents must kill the dragon before it escapes to get the key and escape the dungeon. Basically, 3 agents are grouped together and you can get a reward when you escape the dungeon.

In this environment, at first, the agents seem to be wandering, but as you learn, you can see them quickly escaping the dungeon. The following video is the result of learning about 2 million steps. I was able to quickly kill the dragon and see them exit the dungeon.
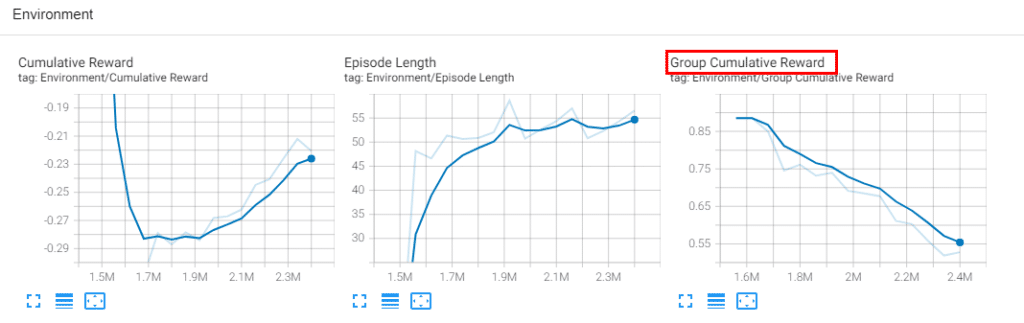
I wanted to give these agents a new environment and test it, so I set up an environment that gave the agent a penalty (-1 point reward) when the dragon was killed to further study. The pretrained model is also well retrained, so I added a new penalty environment to the previously trained model and retrained it about 2 million steps, and I was able to see the dragon actively avoiding (?).
In fact, the expected appearance is that killing the dragon is a penalty for the individual, but in an environment where the group as a whole is rewarded, I expected that the other two agents would act to push one agent away, but such behavior was not shown, and the dragon Because there is a penalty for killing, you can't kill the dragon and get out of the dungeon, so you can see that the group's overall reward is falling. It is linked so that you can see the learning process using tensorboard.
If you have simple knowledge of how to use Unity and learning algorithms, you can create interesting environments and game characters using ML-Agents.
github: https://github.com/Unity-Technologies/ml-agents







