

(https://www.forbes.com/sites/nishatalagala/2021/03/15/artificial-intelligence-in-2021-five-trends-you-may-or-may-not-expect/?sh=15e425135677)
[Service Development Team Im Changdae]
Before DevOps, on-premise servers were called on-premise servers, where each company had its own server, and there were server administrators, developers, and QA. In this situation, if the service could not be accessed, I bought an actual physical server, made a rack, and installed the server by plugging it in. Because I have been developing in this kind of situation, I did not have the concept of DevOps and did not feel the need. However, with the advent of data centers, a server is created with a few lines of code, and with a few lines of code, you can easily and quickly create a service with the desired specifications.
In the Devops environment, developers can even perform deployment and maintenance tasks, which means that the role of bringing in the existing Rack or managing the server has come to the developer. But as you build services and start using them in your business processes, new hurdles are bound to appear. In this case, developers can avoid requesting resources from the IT department by adopting Devops. You can deploy the resources you need on your own, scale when needed, and do the tracking, versioning, and data processing you must do when managing your model yourself.
In this Devops environment, the software development process (code writing -> testing -> packaging -> deployment) is the cycle of ML service development (data collection/preprocessing -> model training -> testing -> deployment) and building the system stably. It has a similar form in that it allows it to be operated and operated.
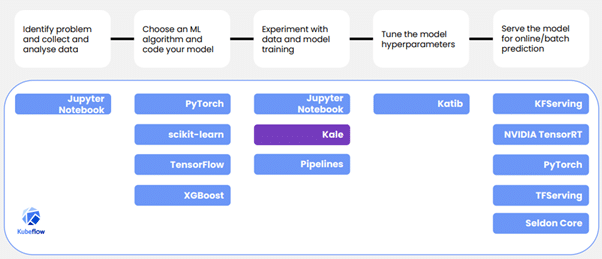
Unlike development in a traditional Devops environment, ML differs in that data management and continuous learning processes are essential:
- Team Skills: In an ML project, a team typically includes a data scientist or ML researcher who focuses on exploratory data analysis, model development, and experimentation. Some of these members may not have software engineers capable of building production-level services.
- Development: ML is experimental in nature. You should try various properties, algorithms, modeling techniques, and parameter configurations to find the one that best suits your problem as quickly as possible. The challenge is to keep track of what worked and what didn't, maximizing code reusability while maintaining reproducibility.
- Testing: Testing ML systems is more complex than testing other software systems. In addition to the usual unit and integration tests, data validation, trained model quality assessment, and model validation are required.
- Deployment: Deploying on an ML system is not as simple as deploying an offline trained ML model as a prediction service. With ML systems, you may need to deploy a multi-stage pipeline to automatically retrain and deploy your model. This pipeline, which adds complexity, requires data scientists to automate steps that must be performed manually to train and validate new models before deployment.
- Production: ML models can suffer from poorly-optimized coding as well as constantly evolving data profiles. This means that this degradation must be accounted for because the model can be compromised in more ways than traditional software systems. So, you need to keep track of summary statistics in your data and monitor the online performance of your model to send a notification or rollback when values deviate from your expectations.
MLOps is an ML engineering culture and practice that aims to unify ML Systems Development (Dev) and ML Systems Operations (Ops). Through MLOps, it would be good to establish an efficient development culture by establishing an automation and monitoring environment at all stages of ML system configuration, including system integration, testing, release, deployment, and infrastructure management.
MLOps: Continuous Deployment and Automation Pipeline for Machine Learning: https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning?hl=ko






