
[Prior Research Team, Jihyun Song]
It's been over two years since I've been interested in the Open Domain chatbot and came across papers about Blender 1.0 and Meena. At the time, there was a question as to how many years would it take to have the plan to have a consistent long-toned conversation and an accurate knowledge response that they claimed would overcome in the future. The reason is that the limitations of the open domain chatbots that have been released so far are very far from human conversations, such as searching based on stored data, babbling when the conversation is long, and giving vague answers to questions about missing information. because of.
However, the blender 2.0 announced by Facebook AI this time overcomes the limitations of the previously presented open domain chatbot and is evaluated to be superior to GPT-3.
In this article, I would like to share the characteristics of the existing model, the summary of the characteristics of blender 2.0, and a review on related papers.
Features of past releases of Google Meena & Facebook Blender 1.0


Features of the recently released Facebook Blender 2.0

Comparing the characteristics of the bots above, the difference between the existing bot and the recently released blender 2.0 is that multi-turn conversations are possible, the persona can be maintained for a long time, and real-time information can be updated through internet search.
If you look at the characteristics of blender 2.0 above (image on the left), GPT-3, which learned a large amount of data, provides past information as an answer and asks a question, whereas blender 2.0 answers the latest information. And while blender 1.0, which was previously released, asks questions vaguely if you do not know the answer, blender 2.0 searches and reflects new information into the conversation to give natural answers. Bot's real-time search function seems to help the other party not only to acquire information but also to continue a natural conversation.
What has Facebook AI done to overcome this limitation? Below is a review of one of the recently published papers.
Review of Papers on Facebok AI Blender : Beyond Goldfish Memory: Long-Term Open-Domain Conversation
In order to overcome the limitations of the long-term memory of the existing open domain chatbot, it is said that the method of summarizing and recalling previous conversations, and retrieving and updating information, performed better compared to the existing models.
- Multi-Session Chat : MSC
In this paper, a data set was constructed with great care to solve long-term memory, and this data was used for fine tuning.- In Session 1, based on the short conversation content of the existing PERSONACHAT, it proceeds as a conversation task in which only brief information of the two people who met for the first time is shared.
- From Sessions 2 to 4, a set period of time (units of 1 to 7 hours or units of 1 to 7 days) is set, and the existing persona is maintained and a conversation reflecting the previous conversation is made. Just like two people who have had a conversation before and are having a conversation again after a while, when the topic expands, it keeps the conversation consistent with the previous conversation.
- Conversation summaries (extended persona) Even if you can see previous conversations between workers and provide an environment where you can understand the history, there is a limit to how people can read and utilize the information within a limited time. Therefore, record and summarize key points in each session to serve as a reference for the conversation.
- Looking at the Dataset statics, MSC has a long number of shots such as 53 to 66 turns compared to the short 2.6 to 14.77 turns previously built.
- Modeling Multi-Session Chat
- Transformer Encoders
BST 2.7B built in the existing blender1.0 is used as a pretrained model, and fine-tune is performed using MSC above. - Retrieval-Augmentation
The search system is used to find and select parts of the context to be included in the final encoding provided by the decoder. - Summarization Memory Augmentation
It consists of two main components.
1. Encoder-decoder digester: This functions to add new information contained in the last conversation, if any, to long-term memory.
2. memory-augmented generator: used to access the conversation context and long-term memory to generate the next answer.
- Transformer Encoders
- Experiments
- Using session dialogue context
- Using summary dialogue context
- Comparing performance on session openings
- Comparing different context lengths
- Summary context performance
- Varying the number of training sessions
- Predicted summary models
- Retrieval-augmentation model
- Summary Memory model variants
- Human Evaluation
We talk up to the 5th session and provide a summary of the previous 4 sessions we talked to.
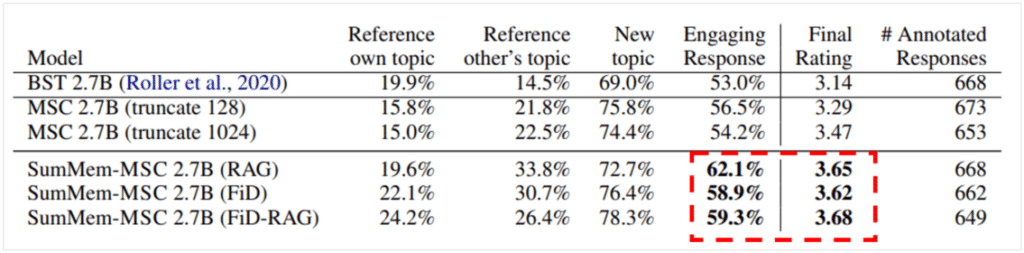
- Conclusion
In this study, the limitations of long-term memory of previous models were overcome by investigating various architectures and collecting data through a new crowd-sourced work, Multi-Session Chat.
Excellent results were obtained in both automatic metrics and human evaluation, and in future work, we will study for the addition of architectures for establishing long contexts and conversations.
Blender 2.0 has added the ability to provide information through real-time search rather than knowledge based on learning while having personalization information similar to that of a person and having a memory. This is an innovation that takes the effort out of training large models.
What chatbot will surprise us next? Google Meena 2.0? Or maybe the Facebook research team is working on the next version, blender 3.0? I look forward to seeing what other high-performance technologies will come out in the future.
References
https://ai.facebook.com/blog/blender-bot-2-an-open-source-chatbot-that-builds-long-term-memory-and-searches-the-internet/
https://arxiv.org/abs/2107.07567






