
[Convergence Research Team Hongmae Shim]
If you pick the top 10 keywords for 2020 in the field of NLP, GPT-3 (Language Models are Few shot Learners) Of course it will be in the rankings. To this day, GPT-3's enormous amount of parameters and excellent performance are still growing in popularity both within and outside the field of NLP. However, as an NLP researcher, the greatest contribution of GPT-3 to cutting-edge research is in general work (especially zero-shot and few-shot). Prompt-tuning I think it proves the applicability of the technology. Before GPT-3, prompt-tuning was mainly used to explore the knowledge embedded (latent) in the language model. In the past two years, a lot of related papers have been pouring out as a very hot keyword.
The mutual achievements of Prompt-tuning and GPT-3 cannot be ignored in the history of NLP development. Prompt-tuning-based GPT-3 performed well in performing various types of tasks, but if you think about it, wouldn't GPT-3 have better zero-shot and few-shot learning capabilities to perform these amazing tasks? Prompt-tuning is the best way to use GPT-3?
Recently, Google researchers have developed a method of instruction tuning that significantly outperforms GPT-3 in 19 out of 25 tasks using fewer parameters (137B) than GPT-3 (175B). FLAN (Fintuned LANguage Models are zero-shot Learners)by suggesting that GPT-3 could be made stronger.
GPT-3 ( LANguage Models are zero-shot Learners) compared to FLANThe difference lies in finetune. FLANThe core idea is to fine-tune various NLP tasks to solve these tasks by transforming them into Natural Language Instructions (a kind of task instruction or instructions). (Refer to (C) in [Figure 1] below)
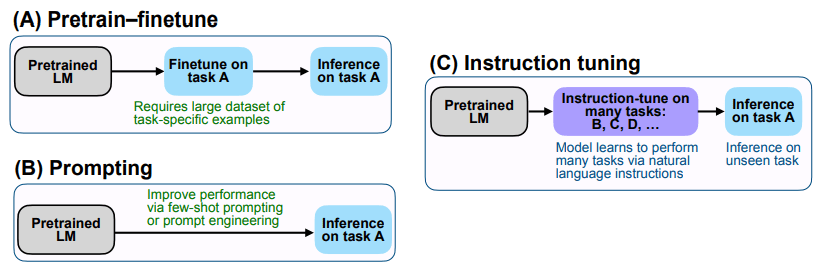
To explain in more detail, FLAN first fine-tunes Pretrained LM so that it can perform many different NLP tasks including translation, common sense reasoning, sentiment classification, etc. For example, as shown in [Figure 2] below, for the translation task, “Translate this sentence to Spanish” and for the sentiment classification task, use the command/instruction “Is the sentiment of this movie review positive or negative?” When the model completes fine-tuning so that it can perform various tasks using information containing these commands/guidelines, the existing knowledge is applied to the command “Does the premise entail the hypothesis?” You can use it better to answer it.
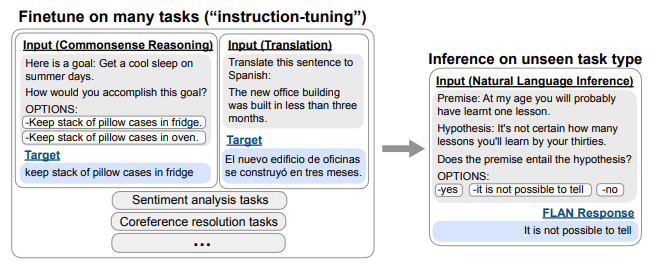
In the paper, the authors found that FLAN can learn to operate even on tasks that have not been explicitly learned after learning about web pages, programming languages, conversations, and Wikipedia sentences. In this way, Instruction Tuning can improve the ability to process and understand natural language by teaching the model how to perform NLP tasks expressed as a kind of command/instruction. This means that we can partially understand the true intentions of natural language.
In FLAN's paper, a tuning experiment was performed by selecting 12 categories and a total of 62 common natural language processing and generation tasks related data. (Refer to [Figure 3])
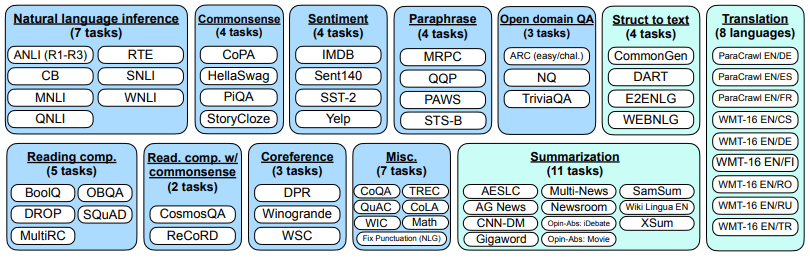
The authors used an autoregressive language model (Base LM) of size 137B as the base language model. The Instruction Tuning pipeline blends all data sets for more than 60 nlp tasks and randomly samples each data set. The number of samples in each dataset varies widely, and some datasets have more than 10 million training samples (eg translations), limiting the final number of training examples in each dataset to 30,000. In the experiments, T5-11B and GPT-3 were used as reference models.
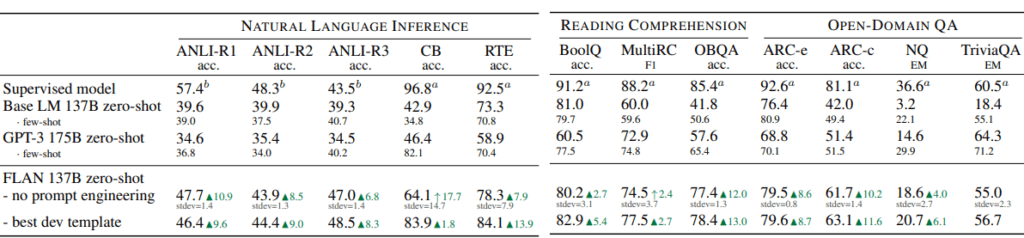
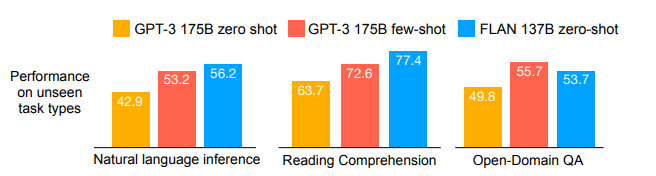
As a result of the experiment, FLAN already performed better than few-shot GPT-3 in the zero-shot scenario in the natural language inference task and QA task, and achieved similar performance to the supervised model in many tasks ([Figure 4], [Figure 5] below. ] Note.) Experimental results for various other tasks are also included in the thesis, so please check the thesis yourself if necessary.
Those familiar with NLP may think that this article is another “A+B” Task (A=prompt tuning, B=Multi-task Learning). However, these A+Bs will be Generic Natural Language Processing Modelto do Solution/MethodI think this could be. First, a large-scale autoregressive pre-training model with hundreds of billions of parameters is trained through a large amount of unlabeled corpus, or an existing training model is selected, and in the second step, these models are You can fine-tune understanding and creation tasks. In a fine-tuning process, using a method similar to course learning, you can first train a lower-level task (e.g. NER identification, sequence semantic annotation) and then train a higher-level task (e.g. logical reasoning, QA). It also learns resource-rich Tasks (eg English/Big Data Tasks) first, then learns fewer resources (eg Other Languages/Low Data Tasks), and uses adapters to keep relevant parts per task in the model. Finally, we provide commands/instructions so that the model can reason about new data and new tasks. If this versatile method is fully utilized, I am looking forward to seeing what new tasks it will be able to perform!
references:
https://arxiv.org/pdf/2109.01652.pdf






