Lip2Wav: Generates a voice signal from silent lip movement
I've heard stories that you can know what you're talking about with just the movements of your lips if you get special training, but the research in the link was realized with AI.
I've heard stories that you can know what you're talking about with just the movements of your lips if you get special training, but the research in the link was realized with AI.
TensorflowTTS, an open source based on Tensorflow 2 that supports several latest TTS models such as Tacotron2, MelGan, FastSpeech, etc., has finally begun supporting Microsoft FastSpeech2. FastSpeech2 shows similar performance to Transformer series TTS, but takes more than twice the time to learn…
MIT's Speech2Face is a study that generates a speaker's face from a speech signal. However, it does not perform speech to face transform with one model, but it combines the results of existing studies for different purposes to create impressive results. (The first author is now...
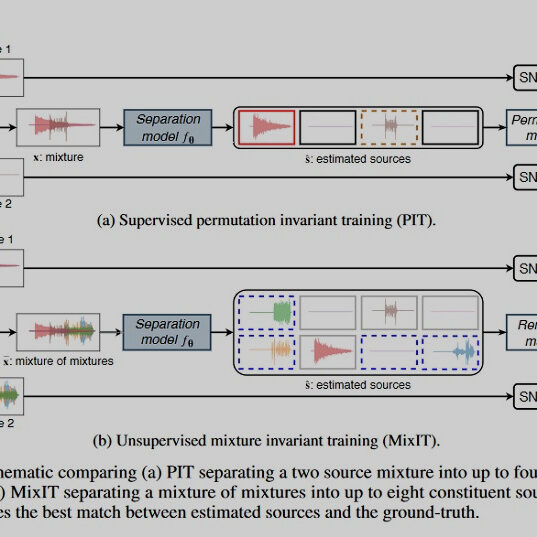
MixIT AI, released by Google, is a technology that obtains a separate sound source from single-channel audio in which multiple sound sources are mixed. It can be viewed as a blind source separation task, and unlike existing technologies, it has the feature of delivering excellent performance with unsupervised(!).
After performing representation training with 53,000 hours of label-free data, a pre-trained model for Facebook's wav2vec 2.0, which became a hot topic because it created a speech recognizer with only 10 minutes of labeled data, was released. No fine-tuning in the representation model,...
There are many complex human emotion perceptions and expressions (e.g. angry emotions affect facial expressions, voices, and language). Here's an open dataset with audio-videos tied together and emotionally labeled. The Ryerson…